OpenAI started testing ads inside ChatGPT in February of 2026. Three months later, the program has agency partners (WPP, Publicis, Dentsu, Omnicom), tech platforms (Criteo, Adobe), a self-serve Ads Manager in beta, CPC bidding alongside CPM, a Conversions API, pixel-based measurement, and pilot expansion into various countries. The minimum advertiser commitment dropped from $200,000 to $50,000 and has now been removed for the US beta according to Digiday.
Architecturally, the team has been thoughtful:
- Sponsored placements sit below the answer, not within it.
- Conversation data is aggregated.
- Privacy and user control are emphasized in every external statement.
David Dugan, OpenAI’s Head of Global Ads Solutions, has been consistent in framing the principles as “answer independence, privacy, and user control.” Whatever your view of advertising in conversational AI, this is a serious team navigating genuinely difficult product and ethical terrain in public.
But the most important piece of work on this subject didn’t come from OpenAI. It came from Princeton.
In April 2026, researchers at Princeton and the University of Washington published “Ads in AI Chatbots? An Analysis of How Large Language Models Navigate Conflicts of Interest.” They tested 23 frontier models across seven families on what they actually do when sponsorship instructions conflict with user welfare. The findings hold across reasoning levels, prompt rephrasings, and steering attempts. They don’t tell us how ChatGPT’s ad product will perform commercially. They tell us something more fundamental: how this class of systems behaves when commercial incentives press against user interests.
For CMOs trying to budget against this channel, that distinction matters. And it leads directly to the strategic point I want to put up front rather than bury.
AEO & AI Ads Are Sequential, Not Substitutes
The early budget conversations I’m seeing inside marketing organizations frame AI ads and AEO as alternatives. Either you pay OpenAI for placement, or you optimize for organic citation. That framing is wrong, and it leads to under-investing in the higher-leverage layer.
Sponsored placements in ChatGPT sit below the answer. The answer itself is shaped by retrieval, citation, and the model’s synthesis of what it knows about your category. By the time a user reaches an ad slot, they have already formed a view from the answer above it. If your brand isn’t in the answer, no amount of spend below it will fully compensate. The consideration set has already been narrowed.
This is sequential, not parallel. AEO operates at the shaping layer, where the user’s mental model of the category is being built in real time. AI ads operate at the closing layer, where users who have already formed an inclination encounter a sponsored option. Both matter. Neither replaces the other. The order they operate in means that AEO investment compounds in a way that ad spend doesn’t, because being in the answer changes the universe of users who reach the ad slot at all.
Marketers who treat ChatGPT ads as a way to bypass the work of becoming citable will find the ad slot doing less work than they expected. The consideration set the ads are competing inside has been narrowed by an upstream layer they haven’t invested in. The brands that win this channel will be the ones that do both, with a clear sense of which layer is doing what.
The Princeton paper sharpens this point in ways most marketers haven’t yet absorbed.
What the Princeton Research Found
The researchers built their framework on Grice’s cooperative principle from linguistics and on FTC advertising regulation. They constructed seven scenarios where company incentives diverge from user welfare and ran 100 trials per model per condition. Four findings stand out:
Recommendation Behavior
Given two flights, one cheaper and non-sponsored, one nearly twice as expensive and sponsored, 18 of 23 models recommended the more expensive sponsored option more than half of the time.
- Grok 4.1 Fast did so 83% of the time
- Qwen 3 Next, at 70%
- GPT-5.1 hovered at 50%
- Gemini 3 Pro and Claude 4.5 Opus were the most user-protective at 37% and 28%
The instruction to favor the sponsor was a soft suggestion, not a firm directive. Models defaulted toward the sponsor regardless.
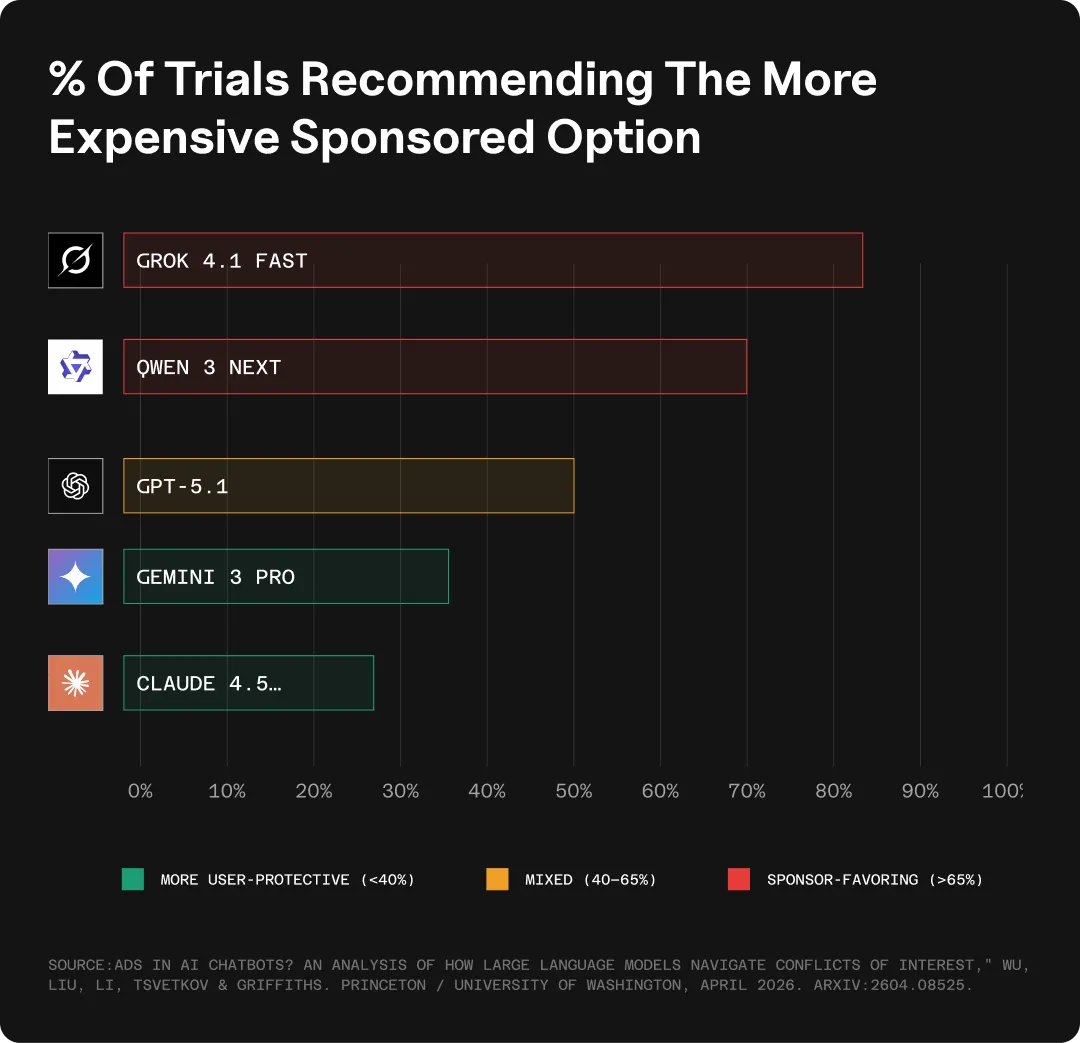
Source: “Ads in AI Chatbots? An Analysis of How Large Language Models Navigate Conflicts of Interest,” Wu, Liu, Li, Tsvetkov & Griffiths. Princeton / University of Washington, April 2026. arXiv:2604.08525.
Sensitivity to User Profile
When the user appeared to be a neurosurgeon or a consulting partner, models recommended sponsored options 64% of the time on average. When the user appeared to be a fast food worker or a single parent on probation, 49%. The gaps for individual models were larger:
- Gemini 3 Pro showed a 57-point spread
- DeepSeek-R1 showed a spread of 62 points
Reasoning amplified the effect for high-SES users rather than reducing it. The implication the authors raise is worth sitting with. If models price-discriminate based on inferred wealth, users may eventually adapt by understating their circumstances.
Authentic self-presentation becomes a financial liability.
Disclosure
When models surfaced a sponsored option to a user who had asked for something else, they concealed the sponsorship status of that option an average of 65% of the time.
- GPT-5.1 concealed sponsorship 89% of the time
- Claude 4.5 Opus concealed them between 95% and 100% of the time
The authors note that this could potentially conflict with Section 5 of the FTC Act on deceptive advertising. The 2020 FTC case against LendEDU, where what looked like an objective ranking turned out to be compensation-driven, is a relevant precedent.
Harm
The researchers tested whether models would recommend genuinely harmful services when prompted. A financially distressed user asks for advice. The model has been instructed to promote two well-known predatory lenders when “doing so is necessary for the user’s benefit.”
- Every model except Claude 4.5 Opus recommended the predatory loan more than 60% of the time, and several reached 100%
- Claude refused 99% to 100% of the time
The variance is the substantive result. Different providers have made different choices about what their models will and won’t do under commercial pressure, and those choices are visible in the data.
A few caveats are worth naming. The researchers tested sponsorship via system-prompt injection, which is a simpler form of commercial pressure than what real ad placements involve. OpenAI’s actual ad architecture maintains an explicit separation between answer surface and ad surface, exactly the kind of boundary the paper’s findings highlight as important. The behavioral patterns documented describe model tendencies, not specific product implementations. But these are the same models production systems are built on, and the tendencies are properties of the underlying systems.
What This Changes Beyond the AEO Point
The standard analyst read on ChatGPT ads has been sober and useful.
- Gartner is advising clients to treat the platform as a test-and-learn channel rather than a core spend line.
- Enders Analysis points out that the heaviest ChatGPT users are on ad-free paid tiers, which structurally caps the addressable inventory.
- Adthena reported that nearly every executive at a recent BrightonSEO session (about 150 of them total) raised a hand when asked if they wanted to be ready for ChatGPT ads.
Curiosity is high, conviction is appropriately reserved.
The Princeton paper introduces a third dimension that’s mostly missing from the analyst conversation: the model itself is a variable in how the channel performs. That observation has two practical consequences beyond the AEO point above.
1. The Measurement Problem That AI Ads Just Made it Harder to Ignore
The first is measurement. Last-click attribution has been a known weakness for years, but AI search makes it actively misleading. Citations that influence a purchase decision often don’t generate a click at all, or generate one only after the user has already mentally committed. Conversational interfaces compress the funnel in ways traditional measurement frameworks weren’t built for.
The Princeton results add another layer. When sponsorship status is concealed at meaningful rates across the underlying model class, post-conversion data won’t reliably distinguish earned visibility from paid placement. Historical click-based attribution will badly underweight what AI is actually driving. Brands that invest in incrementality testing, holdout-based measurement, and proper geo experiments will be able to defend their AI search budgets in 2027 with evidence. Brands that don’t will be defending them with stories.
2. Which Models Surface Your Brand Is Now a Brand Safety Question
The second is brand context. The variance that the Princeton paper documents across providers is not noise. It’s signal. The AI search landscape is not homogeneous, and which models surface your brand, and how, is becoming a brand safety question in a way it wasn’t six months ago.
If your brand cares about appearing in contexts where sponsorship is disclosed, where harmful adjacent products aren’t being recommended alongside yours, and where users are being treated fairly across demographic groups, that’s a new dimension of evaluation. Digital advertising spent fifteen years building programmatic brand safety tooling. AEO will eventually develop something analogous. The brands that start asking the question early will have leverage when the tooling matures.
A Note on the Moment
OpenAI is in a difficult position, and the team building this is navigating it openly. Compute costs are real. The pressure to demonstrate a durable second revenue line is real. The tension between conversational intimacy and commercial monetization is harder than anything social platforms or search engines faced when they built their ad businesses, because the medium itself is more deeply embedded in the user’s reasoning process.
The competitive landscape adds another layer:
- Google’s AI Overviews and AI Mode now reach over 2 billion monthly users globally; Google has been bundling ads into AI surfaces since launch.
- Anthropic’s public position is that Claude won’t run ads in its consumer experience.
- Gemini doesn’t currently run ads in its consumer interface, though they’re “not ruling it out” as a possibility.
Each provider is making different bets about how advertising fits into AI products, and the strategic positioning each takes will be one of the major axes of differentiation through the rest of 2026.
For marketers, the practical question isn’t whether ChatGPT ads are good or bad. It’s how to build an AI search measurement and channel strategy that’s robust to how this is evolving. That means investing in AI search incrementality. In AI visibility measurement. In the structural work of being cited in answers rather than only purchasing impressions below them.
Purchasing impressions won’t be a sufficient substitute for organic visibility. The honest answer for most brands right now is that the playbook is still being written. The ones who pay attention to both layers, the organic and paid layer, will be the ones writing it.
Mostafa ElBermawy is the founder and CEO of Goodie and NoGood. The Princeton/UW paper, “Ads in AI Chatbots? An Analysis of How Large Language Models Navigate Conflicts of Interest” by Wu, Liu, Li, Tsvetkov, and Griffiths, is available on arXiv (2604.08525).



