For two decades, brands wrote for algorithms that ranked pages. Now they’re writing for AI system that retrieves pages, reads, synthesizes them, and decides whether to cite your brand at all. The content strategies that won the last era are actively dangerous in this one.
TL;DR
The discovery layer has moved from a ranking system to a reasoning system. The brands that will lose the next five years are the ones treating this as an optimization problem; using AI to write content that is then read by other AI and summarized for humans who never arrive at the page.
The brands that will win are the ones that return to a simpler question: what do we know, build, or observe that nobody else does? This article argues that durable content strategy in the AI era is not a more sophisticated form of SEO. It is a return to the original question of what a brand is actually qualified to say.
The Dangerous Trap Most Brands Are Walking Into
If you run marketing at a large company today, your team almost certainly uses a large language model to generate content. So does every one of your competitors. So does the AI agent that will eventually summarize all of that content for the customer. This is the single most important fact of the current moment, and almost no content strategy has absorbed it yet.
AI is the new WiFi: ubiquitous, undifferentiated, and invisible in the final product. When everyone has the same model, generative content is a commodity. The marginal article written by your team (based on the same SEO tool recommendations, citing the same public sources, structured with the same H2s) is effectively indistinguishable from the marginal article written by your competitor.
It is also indistinguishable to a human reader, and, more importantly, it is indistinguishable to the retrieval systems now deciding the customer’s first impression of your brand.
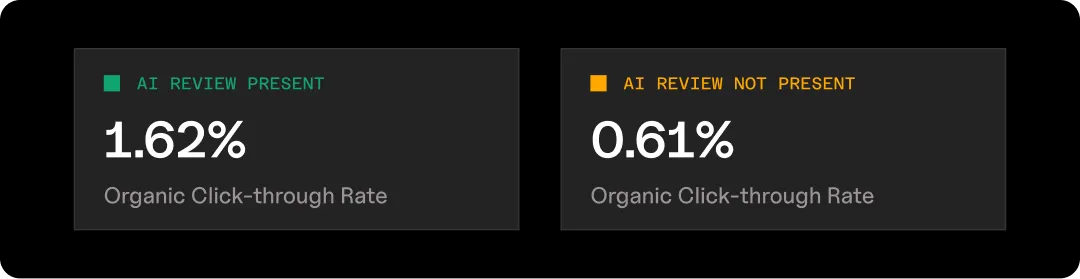
The data is already showing what this looks like in practice. Organic click-through rate is 0.61% when an AI Overview is present, versus 1.62% when it isn’t.
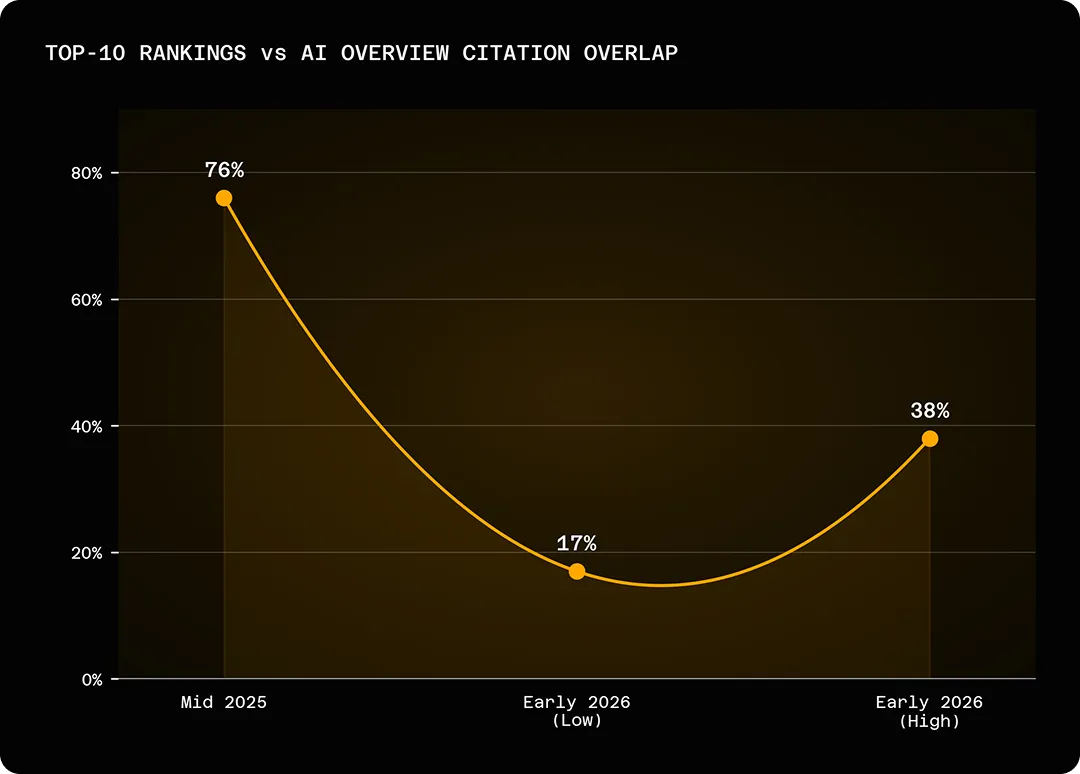
The overlap between top-ten Google rankings and AI Overview citations has collapsed from roughly 76% in mid-2025 to between 17% and 38% by early 2026, meaning the page you paid to rank is no longer the page that gets cited.
HubSpot, the canonical content-marketing flywheel, has been cited as having -70% to -80% organic traffic after years of building broad top-of-funnel content weakly connected to its core product. The educational-article-at-scale playbook, which generated a generation of unicorns, is being compressed into a one-paragraph answer box. That is not a Google penalty. It is the discovery layer doing exactly what it was built to do.
The trap, then, is to respond to this by producing more content, faster, cheaper, using the same models that made the content commodity in the first place. This is the strategic equivalent of printing money during hyperinflation. Every additional page of generic content makes your brand slightly less findable, slightly less trusted, and slightly less worth citing, because it adds noise to a corpus that AI systems are actively trying to filter out.
What Has Actually Changed
It is useful to be precise about what has changed, because the most common framings (“AEO is the new SEO,” “optimize for LLMs”) understate the shift.
- The old discovery layer was a ranking system. It took a query, retrieved candidate pages, and ordered them by a score. Your job was to be near the top of the list. The user did the reasoning: clicking, comparing, deciding.
- The new discovery layer is a reasoning system. It takes a query, retrieves candidate chunks of content from across the web (and from its training data), synthesizes them into an answer, and decides which sources to cite (or whether to cite any at all). The user’s job has narrowed to asking a good question and trusting the answer.
Three consequences follow, and they are the ones most content strategies are ignoring:
- First, the unit of discovery is no longer the page; it is the claim. AI systems pull chunks, not documents. They cite you because you are the source of a specific, credible, extractable claim (a number, a framework, a definition, an observation) not because you wrote a comprehensive guide. Comprehensive guides are now raw material for someone else’s synthesis.
- Second, citation has decoupled from ranking. Roughly 28% of ChatGPT’s most-cited pages have zero organic visibility, and only about 10% of ChatGPT’s short-tail query results overlap with Google’s top results. The signals that earn AI citation (originality of data, entity authority across multiple surfaces, recency, structural clarity) overlap with but are not the same as the signals that ranked you on Google. A brand can be #1 on Google and invisible in ChatGPT, or invisible on Google and frequently cited by Perplexity. Optimizing for one does not produce the other.
- Third, agents are your new persona. Every piece of content now has two readers: the human and the agent. They are not the same reader. The human wants clarity, a point of view, and a reason to trust you. The agent wants extractability, entity consistency, and verifiable claims. A piece of content that works only for humans will not be surfaced. A piece of content that works only for the agent will be surfaced, and the human will bounce. Most content is still optimized for neither.
The Question That Replaces Keyword Research
Here is the question a CMO should be asking instead of “what keywords should we rank for”:
What do we know, build, or observe that no one else can?
This is not a reframing of SEO. It is a reframing of the brand itself. In a world where generic information is free and infinite, the only content worth producing is original content that brings across the brand’s value that no one else could produce.
I call this net information gain (borrowing a term from the retrieval literature), and it is the single most useful test a content team can apply to its own work. Before you publish, ask: if this piece did not exist, what would a reader miss? If the answer is “nothing they couldn’t get from the model directly,” you are adding noise to the corpus, not signal.
Net information gain has to come from somewhere real. In my experience working with hundreds of B2B and consumer brands, it almost always comes from one of five sources:
- Proprietary data. You have access to transactions, user behavior, usage patterns, or market signals that nobody else does. Carta’s regular reporting on startup compensation and dilution is cited constantly by LLMs because Carta is literally the only entity that sees the whole cap table of private-market tech. This is the most durable source of information gain, because it is structurally impossible to replicate.
- Lived operational experience. You have run the thing you are writing about. A CFO writing about SaaS finance, a Head of Trust & Safety writing about platform abuse, a logistics leader writing about port disruption; these people have pattern recognition that a model cannot generate because the patterns were never written down in the first place.
- A community you have earned. You are in a room that outsiders are not in. Specialized Slack groups, professional associations, customer advisory boards, expert networks. What you learn there can be shared (with consent) in ways that are genuinely additive to public knowledge.
- A point of view. You have a framework, a thesis, or a prediction that is specific enough to be wrong. “AI is transforming marketing” is not a point of view; it is wallpaper. “In the next three years, the enterprise CMO role will split into a brand/narrative function and a systems/measurement function, and most current CMOs are qualified only for the first”; that is a point of view. Points of view earn citations because models need something to point at.
- Deep vertical expertise. You have spent ten thousand hours inside a specific domain, and you can make distinctions that a generalist cannot. The best clinical dermatology writing on the open web is cited by every major LLM not because it is SEO-optimized but because the alternative is nothing.
If your planned content cannot credibly claim at least one of these sources, you should not write it. This is the hardest thing for content teams to accept, because most content calendars are built around keyword opportunities, not areas of genuine authority. A mature content strategy in 2026 starts with an honest audit of where the brand actually has the right to speak.
What to Write & What to Stop Writing
The practical implication is that the content shape of a modern brand should look more like a research organization’s output than a blog. Concretely:
- Proprietary studies and recurring reports. If you can credibly produce a periodic index, benchmark, or report based on your own data, do it. Carta’s State of Private Markets, Ramp’s spending benchmarks, Doordash’s restaurant trends; these are cited by LLMs constantly because they represent the only available window into their respective datasets. The internal cost is real, but the content earns citations for years.
- Opinion pieces with a specific, falsifiable thesis. Not reheated thought-leadership. A specific argument, rooted in the author’s experience, that could be proven wrong by a future event. These earn citations because models need a source when they are surfacing a position, and bland consensus content does not read as a position.
- Transparent, criteria-driven curation. The listicle is not dead, but the spammy self-promotional one is. A piece titled “The 10 Best CRMs” is worthless unless the author discloses who was considered, who was excluded, why, and what the evaluation criteria were. Curation with a clear point of view and a transparent methodology is one of the highest-value formats in the AI era, because models use these pieces to triangulate recommendations, and they reward defensible structure.
- Primary reporting and first-hand teardowns. Going to a trade show and writing what you saw. Buying a competitor’s product and using it for a month, and writing it up. Interviewing twenty customers about a specific problem and publishing the themes. Content generated from the physical and social world (not from other content) has a widening premium.
What should you stop writing? The honest answer is most of what you’re writing now. The generic 1,800-word “ultimate guide” compiled from the first page of Google results. The rewrite of your own product documentation as a “blog post.” The thought-leadership piece that could have been written by any other vendor in your category. The keyword-bait glossary page. These pieces no longer pay for themselves in clicks, they no longer differentiate the brand in an AI summary, and they actively dilute the signal of your genuinely original work. If you cannot name the specific reason a reader should read a piece over the model’s default answer, do not publish it.
A useful test I give content teams: if a journalist or analyst read this piece, would they have learned anything? If not, a reasoning system won’t either.
Write for humans first, agents second
Once you know what to publish, the question becomes how to publish it. Here, the discourse has gone badly wrong. A small industry is now selling “programmatic AEO”: template-based generation of thousands of structured pages designed to be extracted by LLMs. Pursued without a corpus of genuine data underneath, this is the 2026 equivalent of doorway pages, and it will age exactly as well. Hacks and spam have short lifespans in systems explicitly designed to filter hacks and spam.
The right sequence is: human first, agent second. Not the other way around.
For the human, the content has to be genuinely worth reading. That means a clear thesis stated at the top. Plain, confident language, not AI-flavored hedging. A voice that reads as if a specific person wrote it. Concrete examples with names and numbers. An argument that moves somewhere, rather than a survey of considerations. Most content written for LLM extraction fails the human test because it was never written for a human in the first place; it was written for a retrieval pipeline and then cleaned up.
For the agent, the same content has to be structurally legible. That is a craft, not a hack. It means:
- Stating the intent of the piece in the first paragraph so retrieval systems can match it to the queries it answers.
- Using headings and subheadings that are themselves informative: headings that read as claims, not as decorative labels.
- Using tables when you have comparisons or data, because tables are the cleanest possible structure for a model to extract.
- Making claims with verifiable sources, including original research, named experts, and dated statistics. Stale statistics are worse than no statistics; models increasingly discount sources whose numbers do not match the current corpus.
- Providing the full E-E-A-T scaffolding: a real author with a real bio and real credentials, a publication date and an updated date, and a visible indication of who reviewed or co-authored the piece. This is the infrastructure of credibility for both humans and machines, and most brands still treat it as an afterthought.
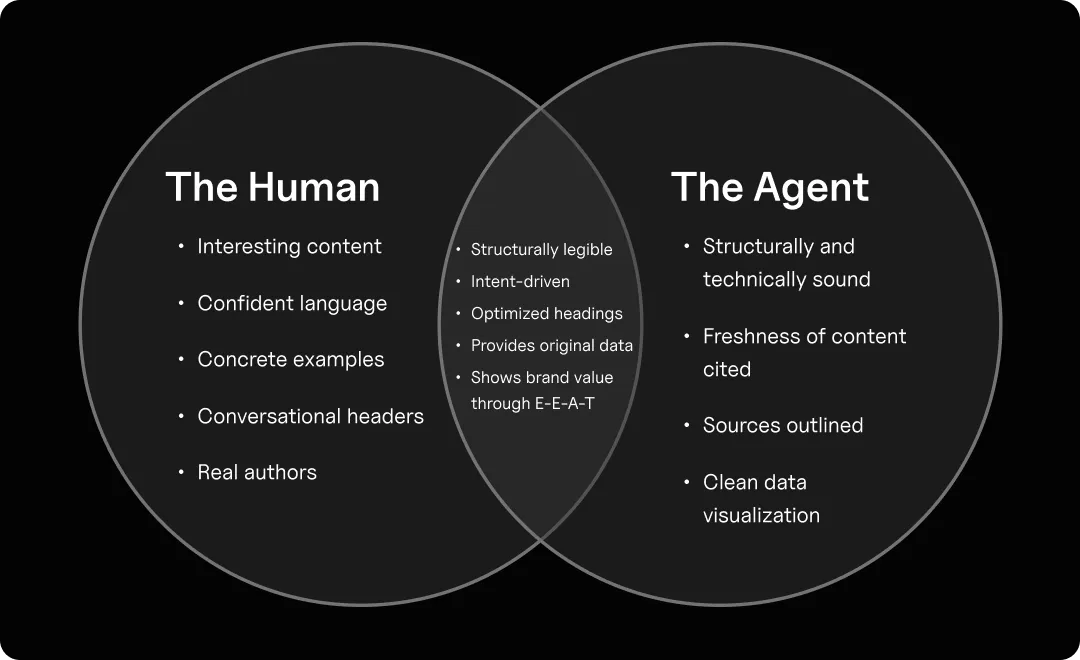
The order matters because the inverse fails. A piece written for agents first reads as synthetic to humans; they bounce, engagement signals degrade, and ironically, the agent-optimized piece stops being surfaced by the agents. A piece written for humans first, with structural legibility layered on top, compounds: humans share it, it earns mentions across the surfaces LLMs train on, and agents are more likely to cite it.
The Metric That Actually Matters
Most marketing organizations are still measuring the old discovery layer by sessions, organic traffic, rankings, and click-through. These were useful when the goal was to bring users to your site. The game has changed, and measurement metrics need to, too. The goal is now to have your brand and your claims represented inside AI answers that the user never leaves; old metrics are lagging indicators at best and misleading at worst.
The right measurement stack for 2026 has three layers:
Citation share. How often does your brand appear in LLM answers to the queries your customers are actually asking. This is measurable (imperfectly, but measurable) by running standardized prompt sets across ChatGPT, Claude, Gemini, and Perplexity at a regular cadence, and tracking both raw citation frequency and share of voice against named competitors. This is the closest proxy to “did we earn the discovery layer” that currently exists.
Sentiment and accuracy of representation. When your brand is mentioned, what is being said? Is it accurate? Is it flattering? Is it tied to the right attributes? A brand can win on citation volume and still lose the customer if the representation is wrong or lukewarm. This is a net-new discipline (closer to PR measurement than SEO measurement) and most content teams are not staffed for it yet.
Downstream, not through-traffic. AI-referred visitors generate 35% more organic clicks when the brand is cited in AI Overviews, and convert at roughly 4.4x the rate of standard organic search because they arrive pre-qualified. The question is not “how much traffic did we get from ChatGPT” (small) but “how much of our pipeline originated in an AI conversation we never saw” (increasingly, most of it). This requires new attribution models, including surveyed attribution (“how did you first hear about us?”), which has suddenly become the most reliable signal available.
The harder, better strategy
If I were taking over content at a major brand today, here is the sequence I would run, in order.
- Audit what you actually know. Before any new content is produced, take a quarter and inventory the brand’s genuine information advantages: proprietary data, operational expertise, community access, defensible points of view, vertical depth, and consistency of brand messaging. Most organizations have far more of this than they publish, and far less of a right to write the things they currently publish.
- Kill the bottom half of the content program. Ruthlessly. Every piece that is generic, undifferentiated, or built purely for keyword capture is net-negative in the current environment — it dilutes the brand’s signal and cannibalizes attention and resources that should fund the top half. This is politically hard because someone owns those pieces and someone approved them. Do it anyway.
- Invest the freed resources in fewer, harder, more original pieces. A single well-executed proprietary study, published annually, will earn more durable citations than two hundred blog posts. Budget accordingly. The right ratio for most enterprise brands is roughly five original, research-grade pieces per year supported by twenty to fifty high-quality points-of-view or curations — not five hundred blog posts.
- Build the human-plus-agent production discipline as a craft, not a script. The best content teams in 2026 look like hybrid editorial-research organizations: a subject-matter expert, an editor, a researcher, and someone responsible for structural legibility and distribution across the surfaces (LinkedIn, YouTube, Reddit, trade press, Wikipedia) that LLMs train on. AI is used for acceleration within this workflow, not substitution of it.
- Measure citation share as rigorously as you once measured rankings. Make it a board-visible metric. Tie it to executive incentives. It is the clearest single indicator of whether your brand is earning a place in the new discovery layer, and it forces every other decision to align.
What this means for strategy
The bet underneath all of this is simple, and it is the same bet that has always rewarded good brands: that in the long run, the market distinguishes between entities that have something genuine to say and entities that are noise. For a decade, the search algorithms of the open web made this bet fuzzy by substituting keyword optimization for substance and getting away with it. The AI discovery layer is re-sharpening the distinction. It is, for all its strangeness, a more honest system. It rewards brands that have done the work of becoming sources, and it punishes brands that have been optimizing their way around that work.
The question every CMO and CEO should be sitting with is not “how do we adapt our content strategy to AI?” It is “is our brand actually the kind of organization that has the right to be cited?” If the answer is yes, the strategy is straightforward. If the answer is no, no amount of structured data and schema markup will fix it, and the first order of business is becoming that kind of organization.
The old content playbook told you to write for an algorithm that was indifferent to whether you had anything real to say. The new one is telling you that the algorithm has started to care. That is, on balance, very good news; for readers, for brands with substance, and for the open web. It is only bad news if you have been getting by without substance. In which case, the sooner you confront it, the better.
Mostafa ElBermawy, Founder and CEO of NoGood and Goodie, writes on the intersection of AI, Search, Growth strategy. This piece draws on work with enterprise brands navigating the shift from conventional search to AI discovery and agentic web.



