Why “blue-link” thinking no longer cuts it
Answer engines like ChatGPT, Gemini, Perplexity, Claude, Copilot – as well as a fast-growing list of vertical models – now handle billions of visits every month. ChatGPT alone recorded roughly 2.6 billion monthly sessions in August 2024, while Gemini, Claude, and Perplexity added another 350 million + combined traffic. Those visits are no longer met with a page of links. They get a single synthesized answer, and that answer either names your brand or it doesn’t.
The brutal takeaway: in AI search, there’s no page-two safety net. You are either visible (named in the answer) or invisible (ignored entirely).
Inside the AI Search Pipeline
Below is the default eight-stage loop most large language models (LLMs) run every time a user asks “What’s the best X?” Understanding it is the first step toward engineering visibility.
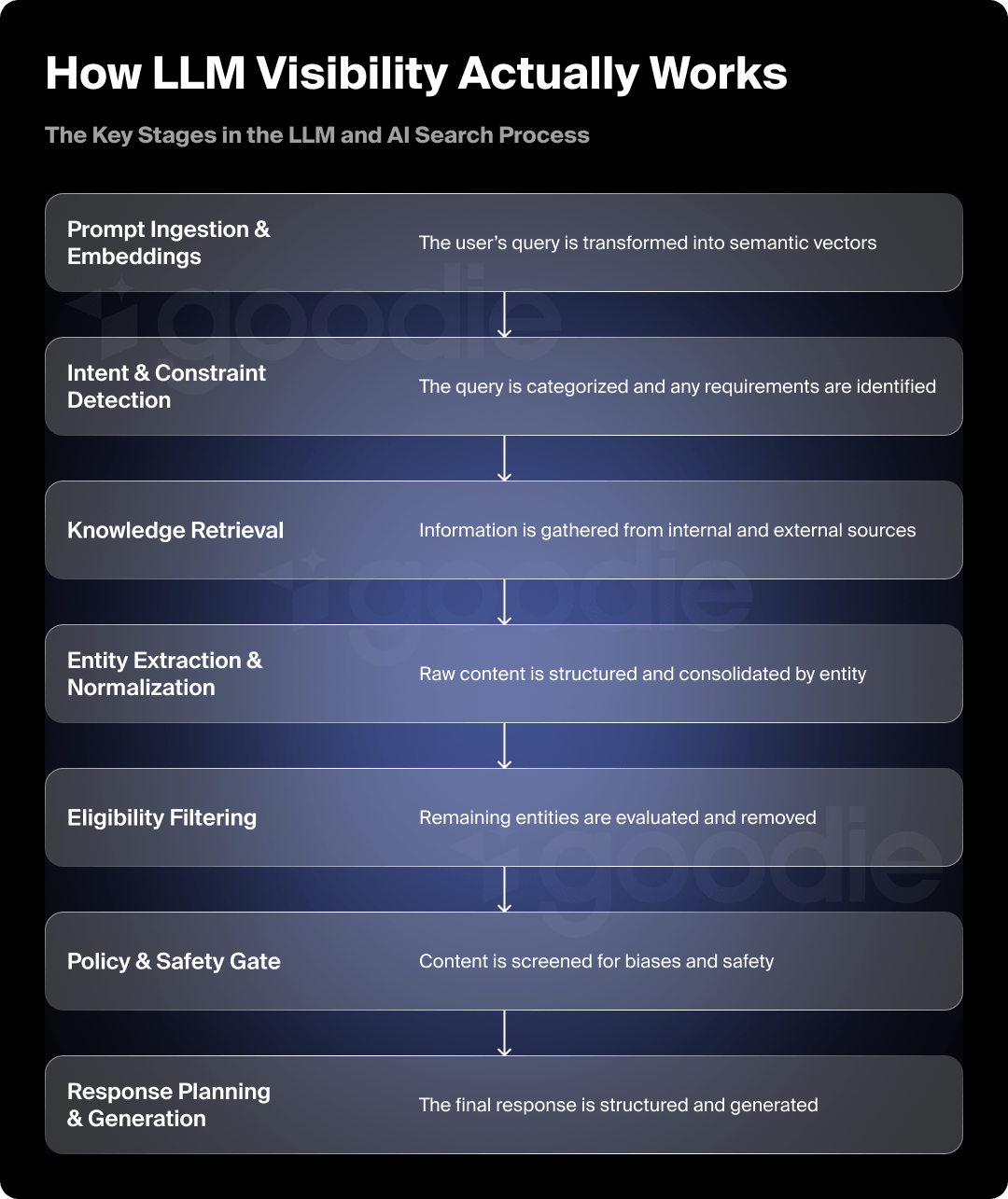
| Stage | What the Model Does | Why It Matters for Brands |
|---|---|---|
| 1. Prompt Ingestion & Embeddings | Tokenizes the query and converts it to a vector in embedding space. | Only the semantic signal in that vector determines which entities are considered downstream. If your name isn’t strongly associated with the topic in vector stores, you start at a disadvantage. |
| 2. Intent & Constraint Detection | Classifies the request (e.g., “product-recommendation, B2B SaaS, mid-market”). | Clear category positioning and consistent descriptor language across the web help the classifier map you to the right segment. |
| 3. Knowledge Retrieval | a) Parametric look-ups inside the model’s own weights. b) Retrieval Augmented Generation (RAG) over external sources. c) Live API calls for pricing, reviews, or specs. | Well-structured public content, machine-readable product specs, and fresh press mentions increase your chances of being pulled into context windows. |
| 4. Entity Extraction & Normalization | Turns raw passages into triples like <Brand, Attribute, Evidence>, merging aliases. | Messy naming conventions or inconsistent branding (“H-Spot CRM” vs “HubSpot”) create leakage at this stage. |
| 5. Eligibility Filtering | Drops entities that violate implied constraints (geo, price tier, tech stack) or freshness thresholds. | Out-of-date landing pages, expired pricing, or region-locked offers can disqualify you before scoring even starts. |
| 6. Relevance Scoring & Ranking | Typical composite formula: Score = 0.35 Feature-Fit + 0.25 User-Similarity + 0.15 Popularity + 0.10 Recency + 0.10 Authority + 0.05 Uncertainty-Penalty | You can directly influence Feature-Fit (clear documentation), Authority (citations), and partially influence Popularity (PR, branded search volume). |
| 7. Policy & Safety Gate | Runs defamation, bias, and safety checks. Swaps blocked entities for the next candidate. | Thin, unverifiable claims or legal disputes can knock you out here, even if you won the ranking round. |
| 8. Response Planning & Generation | Drafts the outline, then autoregressively writes tokens, usually presenting 3–6 diversified options. | Final phrasing is probabilistic, but the ranked table is the underlying source of truth. |
A Live Walk-Through with a Prompt Example
| Pipeline Step | Method |
|---|---|
| Embedding | Query vector sits closest to “CRM”, “mid-market SaaS”, “startup scaling” |
| Intent Tags | task=recommendation, domain=CRM, team_size=25-150, growth_stage=Series A-C |
| Retrieval | Parametric memory surfaces HubSpot, Pipedrive, Freshsales, Zendesk Sell; RAG pulls Q1-2025 Gartner and G2 reports; live API fetches March 2025 pricing tiers |
| Entity Extraction | Example triple: <HubSpot, “high adoption in Series A SaaS”, G2-Spring-2025> |
| Eligibility | SugarCRM Enterprise and Salesforce Enterprise are excluded (too expensive for the detected budget) |
| Scoring | Final scores: HubSpot 0.86, Pipedrive 0.83, Freshsales 0.77, Close 0.74 |
| Policy Gate | All four pass; no conflicts |
| Generation | Model produces an intro, a bullet list explaining each option’s fit, and a caveat on pricing change volatility |
Notice what didn’t matter: whether one vendor has a bigger ad budget. What counted was machine-readable evidence of fit plus the brand’s overall footprint in authoritative sources.
The Visibility Levers Hiding in Each Stage
- Semantic Association (Embedding Stage): Make your category keywords inseparable from your brand name. Consistent co-occurrence in press releases, docs, and social bios helps lock the association into public training corpora.
- Intent Tagging: Publish content that labels itself – e.g., “Mid-Market CRM Pricing Guide” – so classifier signals match your ICP.
- Retrieval Success: Expose clean product specs via schema.org and OpenAPI endpoints; Maintain a public Changelog RSS so RAG crawlers pick up recency signals; Host comparison tables and FAQs structured in <table> HTML, not screenshots.
- Entity Hygiene: Eliminate rogue abbreviations. List official aliases in <link rel=”canonical”> tags and in downloadable brand-style guides.
- Eligibility Resilience: Mirror pricing and regional availability in structured data. If the model sees “US-only” in enough documents, it will silently drop you for global queries.
- Safe-Content Compliance: Maintain an errata page. Models appreciate transparent corrections; it reduces uncertainty penalties.
The Scoring Factors You Can Influence
Research shows brand popularity (search volume) is the single strongest correlate (.334) with ChatGPT visibility. So while feature-fit is table stakes, demand-side signals amplify your rank:
| Factor | Brand Actions |
|---|---|
| Feature-Fit (35%) | Detailed docs, side-by-side technical comparisons |
| User-Similarity (25%) | Publish case studies that mirror target personas (size, stack) |
| Popularity (15%) | Earn press, run PR sprints, drive branded search |
| Recency (10%) | Regular release notes, dated benchmarks |
| Authority (10%) | Secure citations from Gartner, G2, IEEE, reputable media |
Visibility vs. Invisibility: the Common Killers
| Killer | How It Happens | Quick Fix |
|---|---|---|
| Sparse Structured Data | Crawlers can’t parse your features | Add <Product> and <Offer> schema to product pages |
| Fragmented Brand Naming | “AcmeAnalytics”, “Acme-AI”, and “Acme” appear interchangeably | Enforce one canonical name everywhere |
| Out-of-Date Pricing or Docs | The eligibility filter drops you for mismatched budget tiers | Automate doc refresh and include “Last updated” stamps |
| Low Authority Footprint | Few high-trust citations or peer reviews | Pitch Gartner Peer Insights, niche analysts, and university labs |
| Negative Safety Signals | User forum allegations or unresolved controversies trigger defamation guardrails | Publish official responses and third-party validations |
Engineering Visibility: a Hands-On Checklist
Borrowing from emerging Answer Engine Optimization (AEO) frameworks, layer these tactics onto your existing SEO playbook:
- Analyze: Use visibility monitoring tools (like Goodie) to run hundreds of prompts monthly. Record which sources and formats win citations.
- Create: Produce comparison-rich, structured content (tables, bullet lists, FAQs). Feature expert commentary—LLMs weight “unique nuggets” higher than generic copy.
- Distribute: Syndicate that content to outlets LLMs already cite (industry newsletters, G2 reports, Docs sites). Encourage partners to quote or embed your structured chunks.
- Measure: Track visibility share across models. Segment by persona and intent tags. Combine with branded search volume to see if popularity campaigns move the needle.
- Iterate: Refresh data quarterly. Recency is worth ~10 % of the score. A/B test schema tweaks (e.g., sameAs links) and monitor citation lift.
The Road Ahead: Personalization, RAG Everywhere, and Shrinking SERPs
Expect models to weight user-similarity more heavily as they learn individual preferences. Brands will need persona-specific content footprints.
Additionally, OpenAI, Anthropic, and Google are all pushing RAG deeper into their core chat flows. This means that these AI models will be more capable of retrieving fresh, recent content, making it even more important as other sites are punished for their stale content, faster.
Lastly, Gartner forecasts a 25% drop in classic search engine use by 2026 and a 50% drop in organic clicks by 2028. Search – and more specifically, how people search – is changing. User behavior for the first steps of discovery is moving away from the traditional SERPs, and answer engines are that traffic.
Key Takeaways
- AI search is binary: you’re named or you’re not. There is no 2nd page on ChatGPT.
- Visibility is algorithmic: embeddings, RAG, scoring formulas; no pay-to-play shortcut.
- Brand popularity & structured clarity are kingmakers: you are what the internet says about you!
- AEO ≠ SEO: same musical notes, different instruments. Good SEO helps with AEO but AEO is a much wider concept.
- Monitor, iterate, and feed the models: if you don’t publish fresh, machine-friendly evidence, someone else will.
TL;DR for the exec who scrolled here first
AI answer engines decide your brand’s fate through an eight-step pipeline, from embeddings to policy checks. Master the inputs – structured data, authoritative citations, up-to-date docs, and brand popularity – and you’ll tip the model’s scoring math in your favour. Ignore them and your logo never leaves the bench.
The era of Answer Engine Optimization has already started. Time to rewrite your organic growth playbook!



