The State of AEO in 2026
AEO is built on SEO. It does not replace it. Crawlable pages, clear structure, and authoritative content still earn AI citations the way they earned organic rankings. Any framework that tells you to throw out the SEO playbook is trying to repackage what you know.
But the playbook alone is no longer enough, for one reason. To an AI model, a brand is more than what it says about itself on its own website. A brand is the sum of everything the model learned in training and everything it retrieves at the moment it answers. Wikipedia, Reddit, YouTube, review sites, comparison pages, podcasts, news coverage, and forums shape the answer as much as a brand’s own pages, and often more. Those surfaces sit outside the scope of almost every SEO team. In most companies SEO, PR, and social report to different leaders and share no common analytics layer. The result is that no single team can see, let alone control, the full picture of how a brand shows up in AI answers.
This periodic table maps what actually moves that picture. We ran 1.13 million prompts through six AI surfaces, scored each citation outcome against a candidate set of factors, and consolidated the result into the fourteen-factor framework here. The data is correlational, not causal.
The headline holds across every engine we measured: The off-site corpus pulls about as hard as on-page content. Earned Citations and Social & Community Citations both sit in the top tier of the table, and together they outweigh any single on-page content factor. SEO-first frameworks miss this because their tools cannot see it.
What’s New in Version 4
If you haven’t yet read Periodic Table V3 you can find it here, or read the comparison below.
Three things have changed since we published v3 in September 2025.
- Two new factors. Search & Fan-out Rank is now on the table as its own line. It is the single strongest correlate of citation for engines that ground on live search. Originality & Information Gain also gets its own row, broken out from generic “content quality.” The data is clear that derivative-but-well-structured content underperforms original research by a wide margin.
- Explicit weights, not just scores. Every factor in V4 carries a weight, its share of the total 100, alongside the per-engine score. V3 normalized per-model scores without a weighting layer, which made it hard to answer the question the table is actually for: where should I spend my next hour? Weights answer it. They are directional, not precise to the decimal.
- Earned and social citations get surfaced in the weights. They hold 22% of total weight, more than any single on-page content factor. Goodie’s prior social citations research already put a number on the gap: social content drives 2.31 to 4.17 times more AI citations than owned content. v4 is the first edition of the table that surfaces this in the weight column itself rather than the commentary.
- One scope change. We deliberately excluded agentic commerce and shopping surfaces: ChatGPT Shopping, Amazon Rufus, AI Mode Shopping. Product-level visibility runs on different rules (feeds, structured catalog data, agent addressability) and warrants its own index, which we will publish separately.
How the Study Was Built
Data & Scope
1.13 million prompts across six AI surfaces, spanning commercial, informational, and navigational intent across 31 industries, from February 2026 to June 2026.
Prompt distribution weighted toward the categories where Goodie holds active client datasets: B2B SaaS, Beauty and CPG, Retail, Fintech, Travel, and Healthcare.
Each citation outcome was scored against a candidate factor list defined in advance and reviewed by practitioners, then consolidated to fourteen factors. Factors were merged where they measured the same underlying signal and kept separate where they represent distinct, separately ownable levers.
This edition builds on Goodie’s broader citation dataset of more than 58 million citations across 31 industries, and on Goodie’s prior social citations research, which found that social content drives between 2.31 and 4.17 times more AI citations than owned content, with video, led by YouTube, accounting for the largest single share of social citations.
How the Weights Were Assigned
Each weight reflects three inputs:
- The strength of the factor’s correlation with citation outcomes in our dataset.
- How consistently that relationship held across all six engines.
- Whether it is corroborated by the broader body of public AI search research.
Weights sum to 100 and represent each factor’s share of total citation leverage. They are directional, not precise to the decimal.
What a Per-Engine Score Means
Each value from 0 to 100 is the estimated relative influence of that factor on whether a brand is cited or recommended by that engine. A higher metric means the factor has a larger impact on that engine’s citation behavior. The scale is comparative, within an engine and across engines. It is not the probability that a single optimization earns a citation.
What This Study Is Not
- Not a controlled experiment. Citation outcomes are shaped by factors that move together and cannot be fully isolated from observational data. Treat the index as directional.
- Not a fixed constant. Engines change how they retrieve and ground answers often. Re-measure on a cadence rather than treating any single edition as permanent.
- Not a vendor benchmark. The framework is platform-agnostic. Any capable team can act on it.
The Periodic Table
Fourteen factors, ranked by weight. The weight column shows where citation leverage concentrates across all six engines. The per-engine columns show how that leverage shifts from one surface to the next.
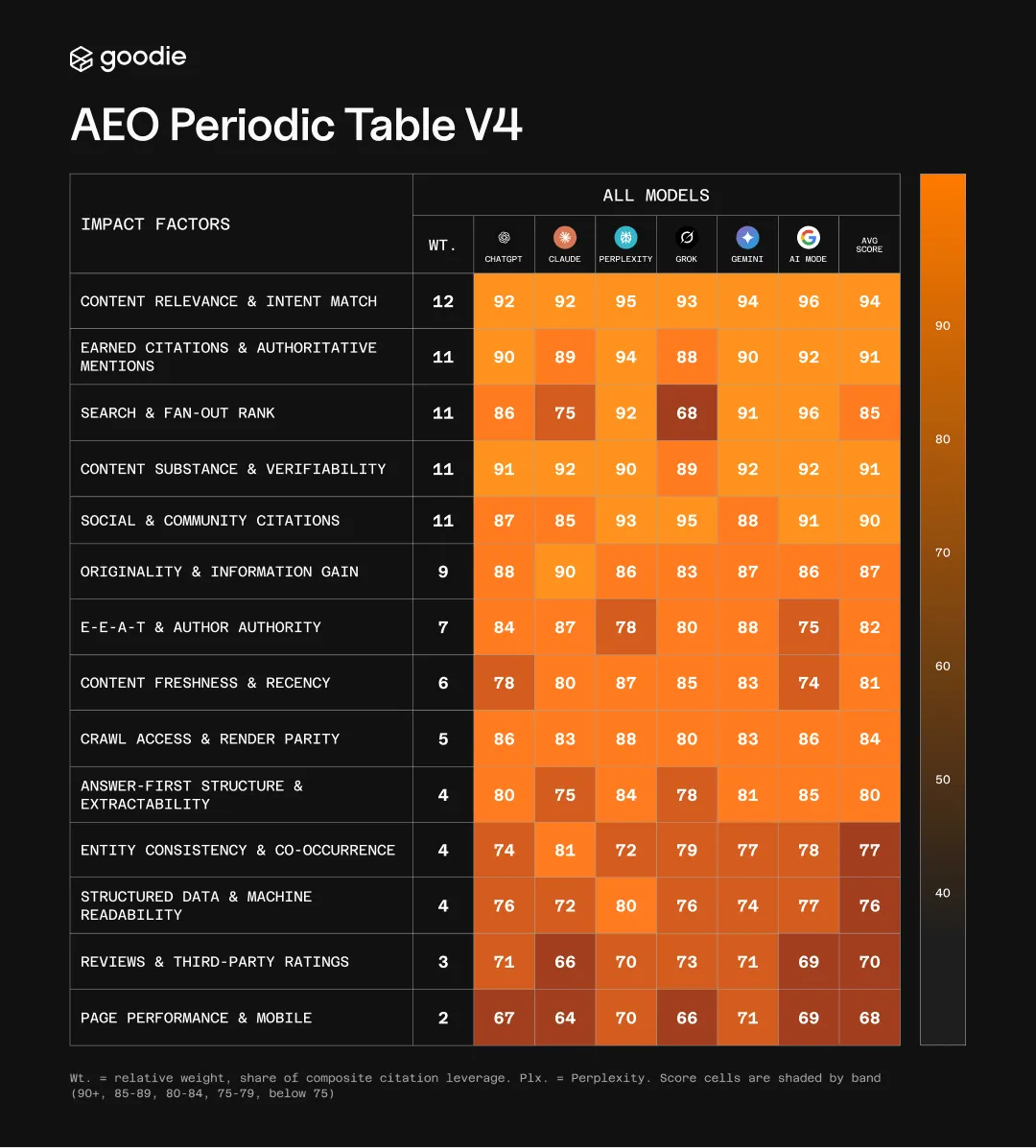
Wt. = relative weight, share of composite citation leverage. Plx. = Perplexity. Score cells are shaded by band (90+, 85-89, 80-84, 75-79, below 75). Numerals shown in mono.
How to Interpret the Periodic Table
- The weight column is each factor’s share of total citation leverage across all six engines combined.
- Per-engine columns show the relative pull of each factor inside that engine. Read across a row to see how much an engine’s behavior differs from the average.
- The average column is the unweighted mean across the six engines, useful for cross-engine programs rather than single-surface optimization.
- Cell shading is graded by score band, not meant to imply precision below 5-point intervals.
What Each Factor Means
| Factor | What It Measures |
| Content Relevance & Intent Match | How closely the page’s topic and angle match the query and the specific intent behind it. |
| Earned Citations & Authoritative Mentions | Third-party editorial coverage and references from credible publications and sites. |
| Search & Fan-Out Rank | Where the page ranks in conventional search for the query and the related sub-queries engines generate. A strong correlate and a proxy, not a direct lever. |
| Content Substance & Verifiability | Depth, accuracy, and the presence of specific, checkable facts a model can attribute. |
| Social & Community Citations | Presence and traction on social and community platforms, including video, Reddit, and forums. |
| Originality & Information Gain | Whether the page adds new information, data, or perspective rather than restating what is already common. |
| E-E-A-T & Author Authority | Demonstrable experience, expertise, authoritativeness, and trust, including identifiable author credentials. |
| Content Freshness & Recency | How current the content is is weighted more heavily for time-sensitive queries. |
| Crawl Access & Render Parity | Whether AI crawlers can reach and parse the page. Covers robots.txt directives for AI user agents (GPTBot, ClaudeBot, PerplexityBot, Google-Extended), server-side rendering versus client-only JavaScript, and parity between what crawlers and users see. |
| Answer-First Structure & Extractability | Whether the answer sits near the top in clear, self-contained passages. Clear placement gives a real lift; rewriting or chunking content only for AI is overstated. |
| Entity Consistency & Co-Occurence | Consistent naming of your brand, products, and people, and how often you co-occur with category terms. |
| Structured Data & Machine-Readability | Schema and clean markup that help engines parse entities and qualify for rich results. |
| Reviews & Third-Party Ratings | Volume, recency, and sentiment of reviews on third-party platforms. |
| Page Performance & Mobile | Load speed, Core Web Vitals, and mobile rendering. A soft signal for AI citation specifically. |
A Note on the Machine-Facing Files: Robots.txt, LLMs.txt & Agent.md
Three machine-facing files come up constantly. They are different in kind and belong in different places. Here is how we rank them for AI visibility.
- Robots.txt is the one that matters most. It is part of Crawl Access, and it is the single most consequential line of configuration in this framework, because its effect is binary. If it blocks an engine’s crawler (GPTBot for ChatGPT, ClaudeBot for Claude, PerplexityBot for Perplexity, Google-Extended for Google’s AI surfaces) you are invisible to that engine no matter how strong everything else is. It earns no citations on its own, which is why it sits inside Crawl Access rather than as its own factor, and it is more consequential than schema or llms.txt. Audit it first.
- LLMs.txt is unproven, directionally sensible, and carries no weight. There is no proof today that publishing an LLMs.txt file changes whether you get cited, and Google has said it does not use it. We are still more optimistic about it than the prevailing dismissal. It works as a readme for machines: a curated map that points agents to the content that matters on a site. For large, complex sites that guidance is plausibly useful, and as agent traffic grows, we expect its value to rise. It costs little and does not hurt. Just do not expect it to move citations on its own today.
- Agent.md is the agentic-commerce file to watch. It is newer and different in kind, and it is not about organic citation at all. It tells AI commerce agents how to interact with a store: what endpoints exist, what product routes are readable, and how checkout and payment should work. On Shopify it is now auto-generated for agentic storefronts and points agents toward the catalog, the sitemap, and the Universal Commerce Protocol and MCP endpoints that power agentic checkout. Because it governs agent transactions rather than answer citations, it sits outside this edition’s scope and belongs in the agentic-commerce index we will publish separately. For any brand selling through AI, it is quickly becoming table stakes.
Reading the Data: What Stands Out
Off-Site Authority Ranks at the Very Top, Factor for Factor
Earned Citations and Social & Community Citations both sit in the top tier of the table, tied with the strongest content and search factors. Together, they hold 22% of the total weight, more than any single on-page content factor. Most SEO-derived programs invert this, putting the overwhelming majority of their effort on owned pages and a thin slice on the off-site corpus. Goodie’s social-citations research puts numbers on the gap: social content drives between 2.31 and 4.17 times more AI citations than owned content. This is the single most important and most underused insight in the framework.
Search Rank Is the Strongest Correlate & the Most Misunderstood
For engines that ground on live search, organic rank is the best single predictor of citations we can observe. That is real, and a framework that ignores it would be dishonest. The trap is treating it as a lever. Rank is downstream of relevance, authority, structure, and freshness. It is the scoreboard those inputs produce, not a dial you can turn on its own. Read it as a leading indicator and invest in the causes. Note how far it varies by engine: it is the top correlate for Google AI Mode and Perplexity, and far weaker for Grok, which grounds on its own ecosystem instead.
Answer Placement Helps; The Rest of the “Rewrite for AI” Advice Is Overstated
Leading with the answer and keeping statements self-contained gives a real lift, because models retrieve passages and structure matters. The broader “rewrite-everything” posture is where the advice runs past the evidence: chunking, “AI syntax,” and restructuring articles for extractability. In our data, those moves often correlate more with the search rank and content quality underneath them than with the rewrite itself.
Results vary by surface and content type. Reference and how-to content responds to a sharper answer-first structure. Long-form editorial rarely does, and sometimes loses something in the rewrite.
We weigh this factor toward the lower middle of the table for that reason. It earns its place, well below the substance, originality, and authority signals that do the heavier lifting.
Originality Beats Schema by a Wide Margin
Originality and Information Gain (86.7 average, 9% weight) sits well above Structured Data and Machine Readability (75.8 average, 4% weight). A brand publishing schema-rich but derivative content underperforms a brand publishing schema-light original research. Schema is worth doing for parsing and rich results. It does not manufacture citations: the most rigorous 2026 tests show engines read visible HTML during retrieval and largely ignore the JSON-LD.
E-E-A-T & Freshness Split the Engines
Claude (87) and Gemini (88) weigh author authority significantly higher than Perplexity (78), Grok (80), and AI Mode (75). Freshness runs the other way: Perplexity (87) and Grok (85) reward recency far more than AI Mode (74) or ChatGPT (78). The reason is architectural. The conservative, training-leaning engines privilege credentialed, durable sources; the aggressively live-grounding engines prioritize what is current. A strategy tuned for Perplexity needs an update cadence; one tuned for Claude does not.
Reviews & Performance Are Over-Invested Relative to Impact
Reviews scored lowest among the off-site factors (70.0 average), and Page Performance scored lowest overall (67.8). Both work, but indirectly: reviews feed sentiment and entity signals more than they earn citations directly, and page speed is a soft signal for AI citation specifically. Meet a reasonable bar on each and spend the marginal hour on original content or earned coverage instead.
Every Engine Is a Different Game
The per-engine columns are the point of this study. The conversational engines, ChatGPT and Claude, lean on what they learned in training, so being a known, trusted entity carries real weight.
The search-grounded engines, Gemini and Google AI Mode, track conventional rank and freshness closely. Perplexity grounds aggressively on live retrieval and runs hot on community and recent coverage.
Grok lives on its own ecosystem and on X.
A program that averages across all six leaves citations on the table in each.
How Each Engine Prioritizes
The lift you get from any tactic depends on which engine you are targeting. Cross-engine programs win by mapping tactics to surfaces, not by averaging tactics across them.
| Engine | What Pulls Hardest | How to Play It |
| ChatGPT | Content relevance, content substance, originality, E-E-A-T | Leans heavily on what it learned in training, so being a recognized, well-covered entity matters as much as any single page. Win the canonical sources: Wikipedia, the consensus explainer pages, the entity graph. Live search supplements that base rather than replacing it. |
| Claude | Content substance, originality, E-E-A-T, primary sources | The most conservative engine. It cites fewer sources per answer and rewards depth, verifiable credentials, and primary-source material. Thin or derivative content rarely makes the cut. |
| Perplexity | Earned and social citations, search rank, freshness, answer-first structure | The most aggressive live-grounding engine. Community platforms and recent earned coverage run hot. Listicles and current, well-structured pages outperform evergreen owned content. |
| Grok | Social citations, especially presence on X; freshness | Citations skew heavily to its own ecosystem and to X in particular. A brand with no presence on X is largely absent from Grok answers regardless of how strong its site or SEO is. |
| Gemini | Content relevance, search and fan-out rank, E-E-A-T, entity consistency | The closest to traditional Google ranking, with extra weight on entity disambiguation and recency. Consistent naming and a clean entity footprint pay off here more than elsewhere. |
| AI Mode (Google) | Content relevance, search and fan-out rank, content depth, answer-first structure | Built on heavy query fan-out. One thorough, well-structured page that answers a question and its related sub-questions beats several narrow keyword pages. Its citation set overlaps strongly with the traditional top organic results. |
What the Broader Evidence Converges On
AEO rests on SEO, but it is not the same job. The surface area is different, the teams are different, and the engines no longer behave the same way.
The public body of AI-search research is still fresh, but it has begun to agree on the following durable points.
- The off-site corpus, especially video and community platforms, is among the strongest correlates of AI visibility, and most programs underweight it.
- Ranking well in conventional search remains one of the best predictors of citation for engines that ground on live search.
- Manipulation tactics, keyword stuffing and inauthentic mention-building fail or actively backfire.
- Clear writing with the answer near the top is enough. Restructuring pages for machines is not where the gains are.
- LLMs.txt has no clear effect on citations today and Google does not use it. Publishing one as documentation for large sites is reasonable, and its importance may grow. Schema helps modestly and consistently rather than decisively: useful for parsing and rich results, not a citation lever.
The Remaining Debate: Domain Authority
Some analyses find link-based domain authority among the strongest predictors of citation; others find little or no relationship. The reconciliation is that domain authority is a proxy, not a lever. It rises alongside the things that actually cause citations: entity recognition, earned coverage, and primary-source presence.
Optimizing for the proxy is a category error. Optimize for the causes, and the proxy follows.
Putting the Index to Work
Five moves that turn this framework into program decisions.
Audit by Surface, Not by Tactic
Stop benchmarking “our AEO program” as one number. Measure visibility on ChatGPT, Perplexity, Google AI Mode, and Grok separately. Each has a different leading factor. A program built around the average underperforms one built per engine.
Rebalance Budget Toward Off-Site
If your AEO effort is more than 70% on-page content work, it is mismatched against the data. Earned and social signals hold 22% of total weight in this study, and almost certainly far less than that share of most teams’ effort. That gap is the clearest arbitrage in the framework.
Build Your Source Map
Take your top 50 category prompts. For each, record which sources every engine cites. Group by domain. The output is a source map: the surfaces you must be present on, and the ones competitors are using that you are not. It is higher leverage than any single-page optimization.
Assign Retrieval Ownership
Most AEO programs stall because no one owns the answer to “why aren’t we showing up for this prompt.” Don’t silo teams, but split accountability across the teams that own each group of factors.
| Owner | Factors They Are Accountable For |
| Content + SEO | Content Relevance, Content Substance, Originality, Answer-First Structure, Content Freshness |
| SEO + Engineering | Search & Fan-Out Rank, Crawl Access & Render Parity, Structured Data, Page Performance |
| PR + Social + Comms | Earned Citations, Social & Community Citations, Reviews & Third-Party Ratings |
| Brand + PR | E-E-A-T & Author Authority, Entity Consistency & Co-Occurrence |
Measure on an AI-Native Layer
Click-based analytics fold AI surface traffic into general web traffic and will not tell you how often a given engine cites you, or what it pulls from in your category. Supplement existing measurement frameworks by tracking citation shares, by engine, over time.
Why Now Is the Right Time to Update the Periodic Table
A fair question, given this is the fourth edition.
Engines change how they retrieve and ground answers often enough that any single edition has a shelf life. Treating one version as permanent gets brands optimizing for a surface that no longer behaves the way the table said it would. We re-measure on a cadence for the same reason an analytics team rebuilds attribution models. The underlying system moves, and the framework has to move with it.
The other reason is method. The aim is for each version to be more useful than the one before it, and for the limitations we name in one edition to be the work we do for the next.
Limitations & What Comes Next
Three things coming in the next edition.
- Causality. Correlation is the foundation; the next edition adds controlled incrementality testing at the factor level.
- Multimodal depth. Video and image inputs are growing as direct citation surfaces. This edition captures video inside Social & Community Citations; a future edition will break multimodal signals out into their own factor.
- Agentic commerce. Shopping surfaces like ChatGPT Shopping, Amazon Rufus, and AI Mode Shopping run on different rules and warrant their own index, which we will publish separately.
AEO is an early discipline. Editions of this table will be revised as the field matures and as engines change how they retrieve and cite. The right posture is intellectual honesty: publish the data, show the method, name the limits, and update.
About This Study
The AEO Periodic Table V4 is published by Goodie, the marketers’ control plane for AI search. It is the fourth edition of an ongoing study. Goodie’s broader research is available here.
Citation. Goodie AI (2026). The Goodie AEO Periodic Table, V4: The brand visibility factors in AI search. Goodie AI Research.



