Key Takeaways
- AI comparison shopping has shifted from returning results to rendering verdicts. Brands that don’t show up as the recommended option are effectively invisible at the moment of decision.
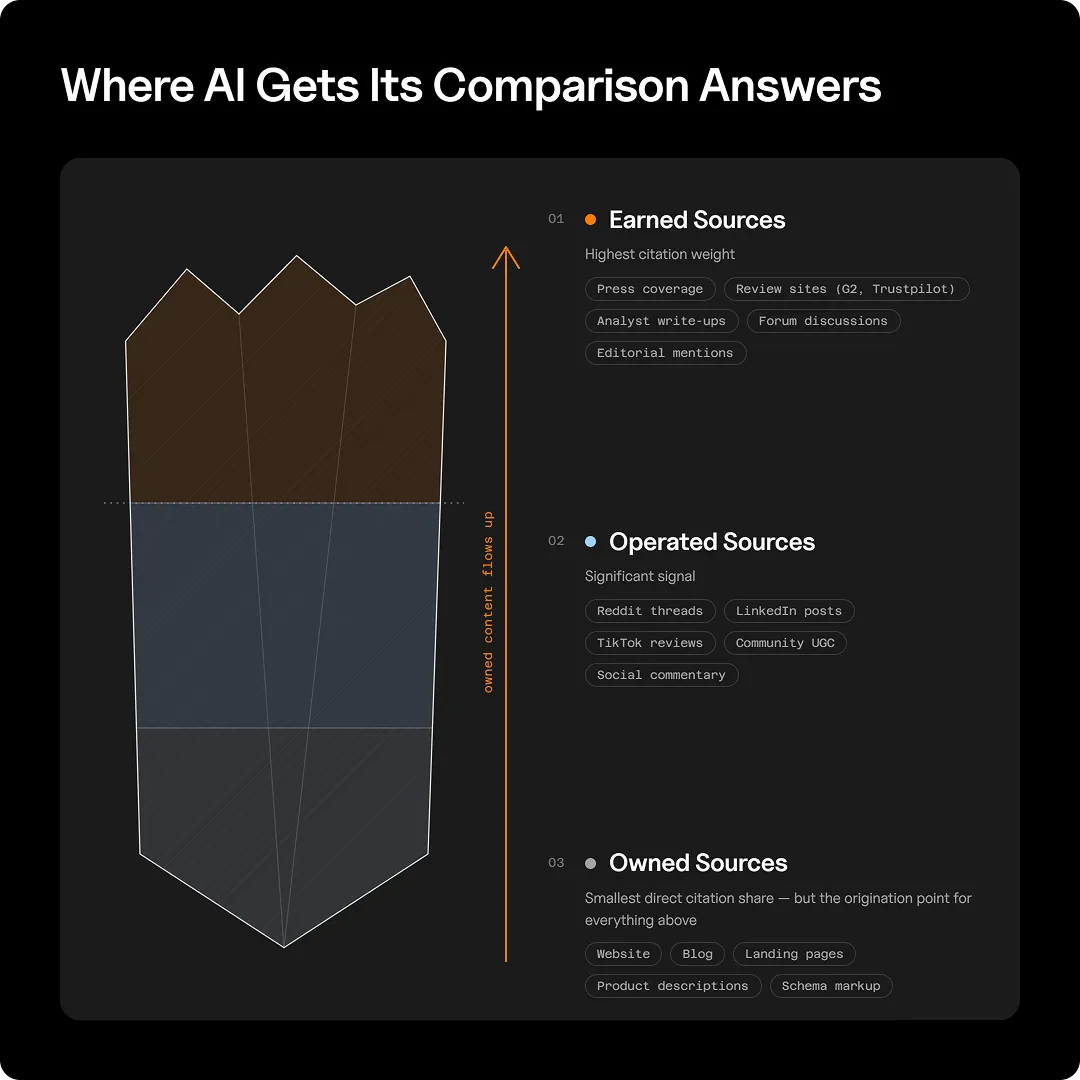
- LLMs build comparison answers from three source layers: earned (highest weight), operated (middle), and owned (smallest direct citation share), most brands over-invest in the layer that matters least.
- Owned content isn’t primarily a citation source, but it is a framing source. It establishes category membership, gives AI the vocabulary to describe you accurately, and anchors the narrative that earned and operated sources echo.
- You don’t need to name competitors to create comparison context. LLMs match on attributes, not brand allegiances. Framing your positioning around use cases, problem types, and who you’re for (and not for) feeds the signals models need.
- AI comparison visibility is a positioning problem before it’s an optimization problem. If you’re not in the comparison set, no amount of content optimization will put you there.
- Monitoring is the prerequisite. Without a baseline understanding of how your brand currently appears across AI models, any optimization effort is a directional guess.
Some of us like to think of ourselves as expert consumers. The kind who only wants to buy a product once (shout out r/Buyitforlife). So when we’ve got our eyes set on something, we want to know exactly what we need to know to make an informed purchase: price range, brand trust, return and warranty policies, materials and composition, brand ethics, style… the list truly goes on.
So when consumers got access to a tool that could run that entire process for them in late 2022, the reaction was predictable: delight. Early LLMs, though, kind of sucked at recommending products. It felt like a game of who’s the biggest, and bigger brands don’t always equal better. Shoppers who prefer small, craft-focused brands found that LLMs like ChatGPT and Claude just weren’t surfacing them the way they wanted.
A lot has changed since those humble beginnings. LLMs have matured, and comparison shopping has become an evolved capability. AI isn’t just answering “what is X?” anymore. It can answer “what is the best X for me?”
Shifting from the consumer lens to a marketing one, that evolution raises a new visibility problem for brands. Because if AI can now render a verdict instead of just a list of links, with an actual recommendation, then the brands that show up as the answer have a serious advantage over the ones that don’t. And unlike traditional search, where you can audit your rankings and see exactly where you stand, AI comparison visibility is largely invisible to the brands being evaluated.
That’s what this piece is about. Not just how to appear in AI comparison answers, but how to be the one that comes out on top; and how to build toward that without waiting for the algorithm to figure you out on its own.
What Is AI Shopping?
AI shopping is the use of artificial intelligence to assist, accelerate, or outright replace the traditional product discovery and decision-making process. Instead of opening 12 tabs, skimming review sites, and cross-referencing specs manually, a consumer can ask an AI agent a single question and get a synthesized answer that accounts for all of it.
But the more important distinction is what AI shopping actually does differently from what came before it. Traditional comparison shopping engines (think Google Shopping, PriceGrabber, or Rakuten) return results. They surface options and leave the evaluation to you. AI shopping renders a verdict. It takes in your parameters, weighs them against what it knows, and tells you what to buy.
That shift from “here are your options” to “here’s what I’d recommend” is small in framing and enormous in implication, especially for the brands on the other side of that recommendation.
What Is Comparison Shopping?
Now moving into comparison shopping, at its most basic level, is the process of evaluating multiple products or brands against each other before making a purchase decision. Price, quality, features, reputation; you’re weighing options to find the best fit for your specific needs. It’s been around as long as commerce itself. Intuitive enough, right?
But what’s changed is who’s doing the comparing. For most of the internet era, comparison shopping meant the consumer doing the legwork, maybe with some help from a price aggregator or review site. Now, AI is increasingly taking on that role, synthesizing sources, applying user-stated preferences, and surfacing a recommendation without requiring the buyer to do the manual work.
That’s a shift in where purchasing decisions are made. If AI is handling the comparison on behalf of the user, then the moment of evaluation happens inside the model rather than on your product page, a review site, or anywhere you can directly observe or influence.
How Does AI Build A Comparison Answer?
When a user asks an AI which product to buy, it doesn’t run a live search and tally up the results in real time. What it actually does is more interesting, as well as more consequential for brands.
Most LLMs generate answers by drawing on a combination of what they learned during training and, in some cases, what they can retrieve in the moment through connected search tools. But even retrieval-augmented models are pattern-matching against signals that were established long before your customer typed their question. The comparison answer a user receives is largely a reflection of how a brand has been talked about, categorized, and evaluated across the broader information ecosystem, not just what a brand says about itself.
That ecosystem breaks down into three source layers, and understanding their relative weight is where most brands’ AI visibility strategies go wrong:
- Earned sources carry the most weight. This is third-party content that exists independently of the brand: press coverage, review sites, analyst write-ups, forum discussions, and editorial mentions. When an LLM synthesizes a comparison answer, earned signals are the most trusted input. They’re external validation, and models treat them accordingly.
- Operated sources, meaning brand-adjacent but not brand-owned channels like social media, community platforms, and UGC, sit in the middle. These carry meaningful signals, particularly for establishing tone, use case context, and the kind of casual social proof that shows up in how real people talk about a product. Reddit threads, TikTok reviews, and LinkedIn commentary all feed into this layer.
- Owned sources are your website, blog, landing pages, and product descriptions. They’re the smallest direct slice of what LLMs cite. This surprises most marketers (it certainly was a hard pill to swallow for me at first). It’s where a lot of AI visibility strategy stalls out.

My immediate question was: if owned content does so little, why bother optimizing it at all?
That’s the right question, with a real answer I spent countless hours coming to. And I’ll get there, I promise. But first, we need to look at the more immediate problem: even before a brand can compete to be the recommended option in a comparison, it has to be considered a viable option in the first place.
The Visibility Gap in Comparisons
When LLMs build an answer, they synthesize signals about reputation, category fit, and comparative standing across the broader information ecosystem. If those signals aren’t present, consistent, and coherent across the right sources, a brand won’t register as a contender regardless of how well its website performs in traditional search.

A Category Membership Problem
LLMs aren’t evaluating every brand on the market every time a user asks a comparison question. They work from an internalized sense of which brands are relevant to a given category, and that sense is shaped by training data, rather than real-time research like most people would assume.
This is particularly consequential for newer brands, niche players, and brands expanding into new categories. Models are forming these associations now, and brands that aren’t present in the right conversations today are harder to retrofit in later.
All that means is that AI comparison visibility is not only an optimization problem, but a positioning problem as well. Solving it requires understanding not just how you’re described when you show up, but whether the conditions exist for you to show up in the first place.
The Owned Content Paradox (& Why It Still Matters)
80-90% of LLM responses rely on earned media rather than a brand’s owned content. So if your instinct is to invest primarily in owned content to win AI comparison visibility, the data suggests you’d be optimizing the smallest slice of the pie.
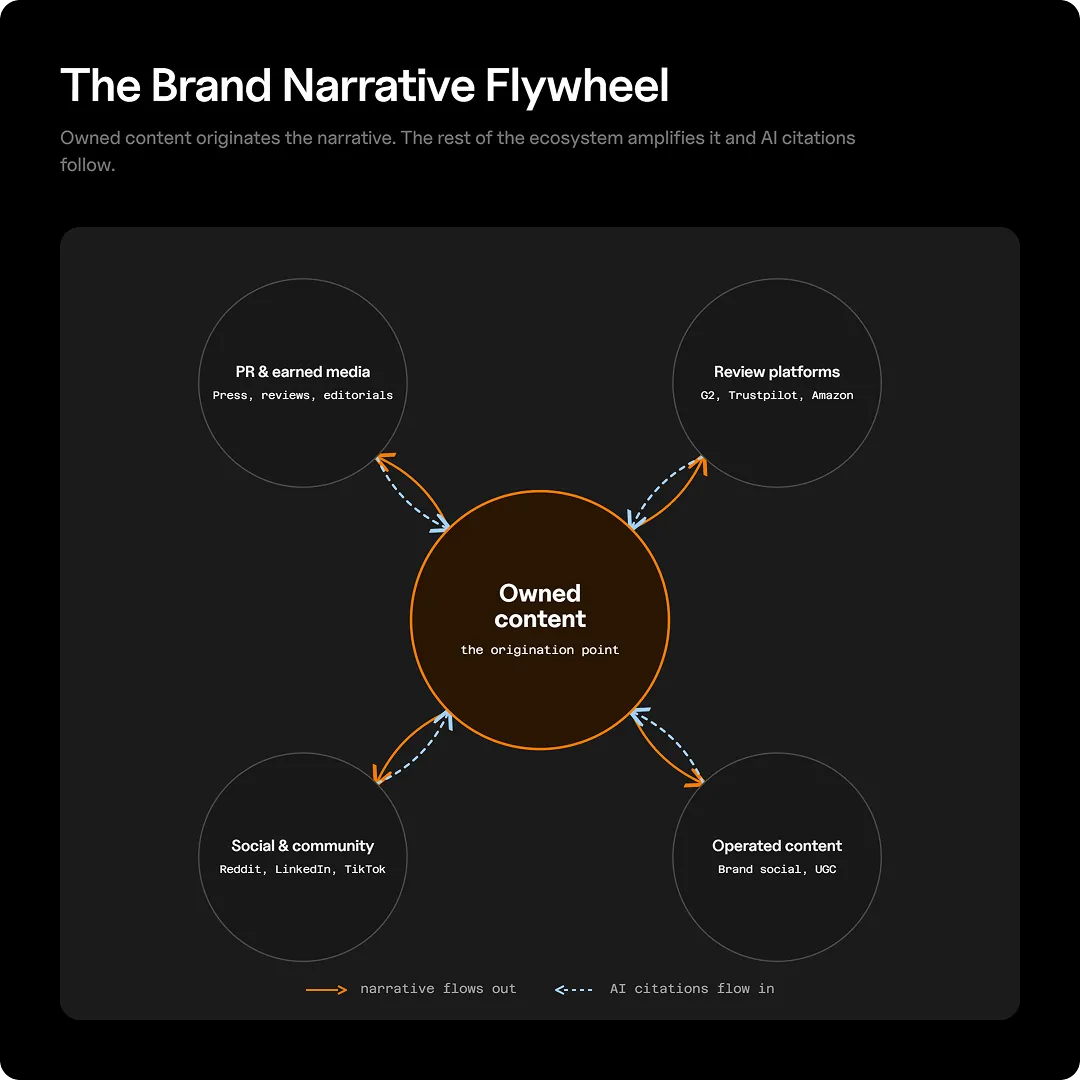
But this is where the paradox kicks in: dismissing owned content because it isn’t directly cited at high rates is the wrong conclusion to come to. Owned content may not be doing the citation work, but it is doing the framing.
What Owned Content Does in AI Comparisons
Think of owned content less as a source AI pulls from and more as the source code for how your brand gets described everywhere else. When a journalist covers your product, when a Reddit user recommends you in a thread, when a reviewer on G2 writes up their experience, all of that earned and operated content reflects language, positioning, and context that originated somewhere. More often than not, it originated with what your brand put out first.
Owned content does three things that the rest of the ecosystem can’t do for you:
1. It Establishes Category Membership
If your owned content doesn’t clearly articulate what category you belong to, LLMs have no reliable anchor to place you in the right comparison set.Brands need a defined “entity definition“: a clear, consistent description of what you are and who you serve that appears across every owned surface. Without it, you’re leaving that framing to chance.
2. It Gives AI The Vocabulary To Describe You Accurately
LLMs are pattern-matching on language across sources. If your owned content uses vague or inconsistent terminology to describe your product, that ambiguity gets amplified when earned and operated sources pick it up. Our AI-friendly content guide is explicit about this: entity precision, factual consistency, and semantic clarity on owned pages are prerequisites for being accurately represented in AI answers, including comparison answers.
3. It Anchors the Narrative That Earned Sources Echo
Distributing content to a wide range of publications can increase AI citations by up to 325% compared to only publishing on your own site, but that distribution strategy requires something worth distributing.
Owned content is the origination point. It’s what your PR team pitches, what review sites reference, and what community members link to. The citations happen elsewhere, but the narrative starts with you.
This is an area where I see most brands struggle. They silo their owned content teams and strategy, keeping it from performing at its maximum potential. Content is the foundation that should inform SEO, AEO, lifecycle, paid search/social, organic social, CRO, design, and really, just every other marketing initiative.
The Schema Layer Nobody Talks About
There’s also a more technical dimension to owned content’s role that often gets overlooked. Schema markup for AI search gives LLMs structured signals about what your content is, what category it belongs to, and how it relates to other entities. Product schema, FAQ schema, and review schema are part of how AI systems build confidence in your brand’s identity and offering.
Research confirms that AI systems prioritize brand authority and content comprehensiveness over traditional link-based signals, and that brand search volume (not backlinks) is the strongest predictor of AI citations. Owned content, done well, builds both. It increases branded search volume by giving people something to search for, and builds comprehensiveness by covering your category with depth and clarity.
The bottom line: don’t optimize owned content expecting it to be cited directly at scale. Optimize it to be the most accurate, structured, and clearly framed version of your brand that exists anywhere, because everything else builds on top of it.
How to Create Comparison Context Without Naming Competitors
Here’s a conversation that happens a lot in brand marketing meetings: someone suggests creating content that positions the brand against alternatives in the category, and someone else immediately pumps the brakes. “We don’t want to name competitors.” “Legal won’t like it.” “It feels beneath us.”
Those instincts aren’t wrong, exactly. Direct competitive callouts can backfire, feel aggressive, and can create legal headaches depending on your industry. Google penalizes self-promotional content anyways, and it wouldn’t be outlandish to assume that LLMs will soon follow suit. But still, that hesitancy often leads to a different problem: brands that say nothing comparison-relevant end up with nothing for LLMs to work with when a user asks “what’s the best option for X?”
To that I say, you don’t have to choose between competitive silence and competitive aggression. There’s a middle path, and it’s actually more effective for AI visibility purposes anyway.
Why LLMs Need Comparison Context
When an AI builds a comparison answer, it isn’t just looking for brands that claim to be good. It’s looking for signals that help it understand how options differ: what attributes matter, what trade-offs exist, what use cases favor one approach over another. That comparative context is what allows a model to synthesize a recommendation rather than just list names.
If your brand’s content ecosystem doesn’t contain that kind of comparative language, the model has to borrow it from somewhere else, often from sources that frame the comparison on terms that favor whoever was most vocal (or paid the most for the top placement in the earned source). Brands that don’t define their own positioning vocabulary cede that framing to competitors, review sites, and third-party aggregators who may not represent them accurately.
How to Feed Comparison Context Without Direct Naming

The key insight here is that LLMs are matching on attributes, not brand allegiances. They’re looking for structured signals about what a product does, who it’s for, and how it differs from alternatives. You can provide all of that without ever writing a competitor’s name.
Define the Category On Your Own Terms
Every category has multiple ways to be described, and the way you frame it shapes which comparison set you get placed in. A project management tool that describes itself primarily as “task tracking software” will be placed in a different comparison set than one that leads with “cross-functional collaboration platform.” Be deliberate about the category language you use across owned and operated content, because LLMs will use it to decide where you belong.
Name the Problem, Not the Competitor
Instead of “unlike [Competitor], we don’t charge per seat,” try “for teams that have been burned by per-seat pricing models, our approach is structured differently.” You’re surfacing the same comparison signal, pricing model differences matter in this category, without the direct callout. The LLM gets the attribute; your legal team stays happy.
Use “Compared to Traditional Approaches” Framing
Language like “unlike rule-based tools,” “compared to manual workflows,” or “for teams who’ve outgrown spreadsheet-based tracking” creates comparison context that’s category-relevant without being brand-specific. It signals to AI systems that your product occupies a distinct position in the landscape, which is exactly the signal needed to show up in differentiated comparison answers.
Be Explicit About Who You’re For & Who You’re Not
This is one of the most underused positioning moves in owned content. Saying “built for mid-market teams who need X, not enterprise platforms designed for Y” does two things at once: it establishes your category fit for the right audience, and it implicitly draws a distinction from alternatives without naming them. LLMs use factual anchors like these to build confidence in a brand’s entity identity; consistency of this language across owned and earned channels directly reinforces that reliability.
Feed the Attributes AI Uses in Comparisons
Think about the dimensions users care about when comparing options in your category: pricing transparency, integration depth, ease of onboarding, support model, use case specificity. Make sure your owned content addresses all of them clearly and directly. AI comparison answers are built from attribute signals, and brands that don’t surface those attributes in their content leave gaps that competitors or inaccurate summaries fill in.
The Earned Content Amplification Loop
One more thing worth naming here: the comparison context you build into owned content only gets more powerful when it’s reflected in earned and operated sources. Our social citation study found that social content generates roughly 2.5 times more AI citations than owned brand pages. This means that the positioning language you establish on your site needs to make its way into your social presence, your community participation, and your PR narratives to fully activate.
When a journalist covers your product using the category framing you defined, when a Reddit commenter recommends you using the same use-case language from your site, when a LinkedIn article references your differentiators in their own words; that’s the loop working. Owned content sets the vocabulary. Earned and operated content amplifies it at a scale that AI systems actually cite.
The result is comparison visibility that doesn’t require naming a single competitor. Just a clear, consistent, well-distributed answer to the question: why this, for who, instead of what?
Tools for Monitoring & Building AI Comparison Visibility Strategy
You can’t optimize what you can’t see, and in AI comparison shopping, what you can’t see is a lot. The good news is that you just need to cover the right layers: the earned signals feeding AI answers, the review data shaping trust, the content gaps limiting category membership, the social conversations training tomorrow’s models, and the visibility layer that shows you how all of it is actually landing.
Here are five tools worth knowing across that workflow:
- Muck Rack: Since earned sources carry the most weight in AI comparison answers, strategic PR is now an AI visibility lever. Muck Rack’s Generative Pulse feature shows which journalists and outlets are most frequently cited in AI-generated answers, so you can prioritize outreach toward coverage that moves the needle in LLMs.
- Yotpo: In AI comparison shopping specifically, reviews are load-bearing. Verified reviews with specific product attributes help AI models form a more accurate understanding of a brand, directly influencing whether products surface in generative answers. Yotpo helps ecommerce brands collect, structure, and syndicate review content in ways AI systems can parse and cite, including schema markup and Google Shopping Graph integration.
- MarketMuse: Before a brand can win an AI comparison, it has to belong in one. MarketMuse helps identify the topical gaps that prevent category membership: the subject areas and attribute signals competitors cover that you don’t. Rather than analyzing content page-by-page, it evaluates content inventories to identify strategic opportunities, gaps, and priorities at scale.
- Brandwatch: The conversations happening about your brand across Reddit, LinkedIn, and social platforms shape your AI comparison standing. Brandwatch tracks brand mentions, sentiment, and conversation trends across social channels, giving teams visibility into the operated source layer that’s often the most influential and least monitored part of the AI citation stack.
Goodie
The tools above each cover a layer of the ecosystem. Goodie covers what happens when all those layers interact: how your brand is actually being described, positioned, and recommended across AI models right now.
AI visibility monitoring tracks brand appearance across ChatGPT, Gemini, Perplexity, Claude, and more, surfacing not just whether you’re mentioned but how you’re being framed in comparison contexts specifically. For brands that need to know whether their earned coverage, review signals, content strategy, and social presence are translating into actual AI comparison visibility (and where the gaps are) it’s the layer the rest of the stack doesn’t cover.
Additionally, the Agentic Commerce Optimizer extends that further for ecommerce brands, addressing the product data and PDP signals AI shopping assistants use at the moment of purchase intent.
What an Activated AI Comparison Shopping Visibility Strategy Looks Like
Winning AI comparison visibility isn’t a checklist, it’s a system. The brands that consistently come out on top are the ones that have built coherent, distributed signals across every layer of the ecosystem consistently enough that AI models have no ambiguity about who they are, what category they belong to, and why they’re worth recommending.
That starts with four moves:
- Lock your positioning language. Decide how your brand should be described in one or two sentences and make it consistent across every owned surface. LLMs use these as factual anchors. Inconsistency erodes the entity confidence that comparison answers depend on.
- Build for category membership before you optimize for ranking. If you’re not showing up in AI comparisons at all, the problem usually isn’t how you’re described, it’s whether you’re recognized as belonging in the comparison set at all.
- Treat earned and operated content as your primary visibility levers. Owned content sets the vocabulary, but the signals AI weights most heavily live outside your domain. A PR strategy, a review generation program, and an active social presence are the core of AI comparison shopping visibility.
- Monitor before you optimize. Without a baseline understanding of how your brand currently appears in AI comparison answers, optimization efforts are directional guesses. Knowing where you stand is the prerequisite for knowing what to fix.
The window for building this as a first-mover advantage is still open, but it’s narrowing. Investing today compounds toward a future where AI comparison shopping is the default, and being the recommended option is worth more than any ranking ever was.



