.svg)
Get a Demo
Interested in trying Goodie? fill out this form and we'll be in touch with you.
Oops! Something went wrong while submitting the form.
.svg)
.svg)


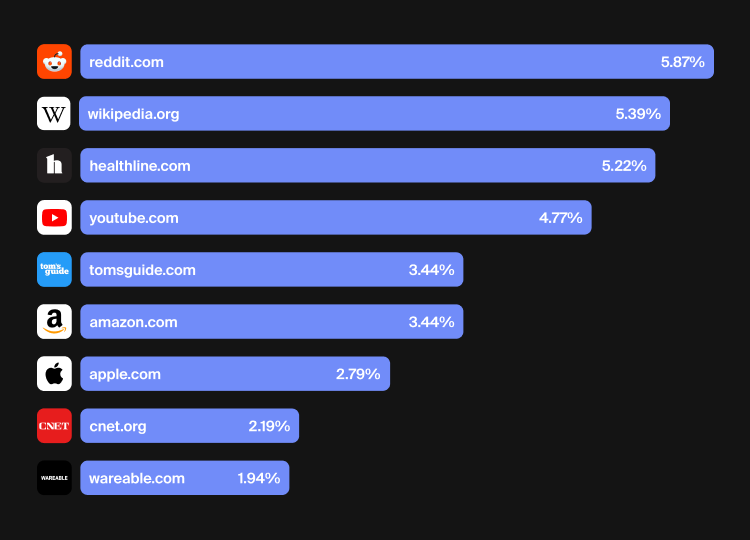
Advanced large language models (LLMs) now directly synthesize answers, often without the user clicking any “blue links.” This has changed the nature of search behavior as a whole: Google SERPs are now dominated by AI Overview (for 60% of searches, in fact), and users are increasingly turning directly to LLMs for answers or information rather than clicking links until they find what they seek. To be exact, 60% of Google’s searches are zero click in 2026. This shows us that users are finding their answers directly in the Google AI Overviews.
Because of this change in search behavior, simply ranking #1 in Google’s search results using traditional SEO methods no longer guarantees visibility (especially if AI can serve up the answer directly within seconds).
One key to Answer Engine Optimization (AEO) is making your website AI-friendly. That means understanding how LLM crawlers (the bots that feed content to AI models) differ from traditional search engine crawlers, and how to use files like robots.txt and the emerging LLMs.txt to your advantage.
In this guide, we’ll break down the differences between AI and search crawlers, tackle crawlability challenges (like rendering and timeouts), outline best practices to keep your content in top shape for AI bots, and provide a detailed look at LLMs.txt and robots.txt, including how they work together.
Before diving into the specifics, it’s important to understand what LLM crawlers are and how they operate differently from Google’s or Bing’s usual bots. Traditional search engine crawlers (e.g. Googlebot, Bingbot) scour the web to index content for search results, building an index so they can rank pages on a SERP.
In contrast, LLM crawlers crawl webpages to gather information for an AI model; either to train the model’s knowledge base, or to fetch up-to-date info for answering queries. In essence, they help create a library of resources that LLMs rely on to answer user questions instead of just generating a list of search links.
The differences between LLM bots and traditional search bots can be broken down into three key categories: Purpose, Behavior, and Impact on Traffic.
Search bots index pages to later retrieve links for queries. LLM bots, on the other hand, crawl pages to supply AI systems with content that might be later used within an answer.
For example, when an answer engine like Perplexity responds to a question, it may have already crawled and ingested content from several sites, which it then quotes and summarizes on demand.
Examples of LLM Crawlers: Each major LLM or AI search platform has its own bot. OpenAI’s GPTBot and Anthropic’s Claude Crawler are two prominent ones. Other examples include Google-Extended (used by Google and other AI systems for training data) and many more research or startup AI crawlers.
To put the power of these LLM crawlers into perspective, when put together, requests generated by GPTBot and Claude in just one month of late 2024 made up about 20% of Googlebot’s requests from the same timeframe.
These bots identify themselves via User-Agent strings (e.g. GPTBot for OpenAI, Google-Extended for Google’s AI crawler, etc.), which we can target in robots.txt.
Traditional crawlers like GoogleBot have become very advanced: they execute JavaScript, respect crawl budgets, and avoid overloading sites. Many AI bots are newer and less sophisticated in their crawling behavior. They may not render client-side scripts, and some operate with shorter timeouts or simpler link discovery.
This means that it is imperative to serve as much pertinent info in HTML as possible. If there is JavaScript on the page, LLM bots will likely not crawl it. In addition to this, if important info lies underneath JavaScript (such as information hidden in a dropdown), it will likely not be crawled even though it is in HTML.
In short, structure your most important info at the top of the page simply and smartly.
AI crawlers often perform two roles: one set of bots gathers broad data for training the model, and another set (for some platforms, like ChatGPT’s search feature) does real-time crawling for Retrieval-Augmented Generation (RAG), which allows it to pull in fresh data when the AI needs up-to-the-minute info.
For example, an LLM might use a real-time crawler to fetch today’s news while relying on its training index for older knowledge.
Don’t be surprised to see AI bots in your traffic logs. As noted, OpenAI and Anthropic’s bots are already crawling at significant scale. Unlike human users, these bots won’t show up in analytics dashboards as pageviews, but they consume bandwidth.
If you run a popular site, a wave of AI crawlers could hit your pages. The upside is increased chances of your content being used in AI answers; the downside is potential load on your servers if not managed well.
You’re probably familiar with robots.txt: a file that tells crawlers what they can’t access. LLMs.txt is a newer concept often described as a “robots.txt for AI models.” But instead of blocking bots, LLMs.txt is about feeding content directly to them in a structured way.
LLMs.txt is essentially a special text (Markdown) file at your site’s root (yourdomain.com/llms.txt) that provides a curated guide to your site’s important content, specifically for Large Language Models. The idea was proposed in 2023 as LLMs started becoming mainstream.
Think of it as a cheat sheet for AI: it points to your most valuable pages (especially things like documentation, FAQs, product info, and policies) in a simplified format that an LLM can easily consume.
Unlike robots.txt, LLMs.txt doesn’t use “Disallow” rules or tell bots what not to do. Instead, it highlights what content the AI should focus on. For example, you might use LLMs.txt to say, “Hey AI, here’s a quick overview of our site and links to our key resources.” This can help the model understand your content without wading through unnecessary stuff like navigation menus or ads.
The LLMs.txt file is typically written in Markdown, which is both human-readable and easy for machines to parse. There’s a suggested structure that has become common:
For example, an LLMs.txt for a company might look like:

In this hypothetical snippet, the website owner has created Markdown versions of key pages (e.g. the API page and the Features page) and listed them. The LLMs.txt provides an at-a-glance map of the site’s crucial info. An AI crawler could fetch this single file and quickly know where the “good stuff” is, rather than guess by crawling every page.
The goal is to remove ambiguity by giving AI a prioritized content list.
Now, it’s important to set expectations. LLMs.txt is not yet widely adopted by the major AI players. OpenAI’s GPTBot, Google’s crawlers, and others do not currently check for or use LLMs.txt by default.
Google’s own search representatives have even likened LLMs.txt to an early, unused idea: the old meta keywords tag in terms of current impact. Many webmasters who implemented LLMs.txt reported that known AI bots never requested the file at all. In one case, thousands of domains saw virtually zero hits on LLMs.txt except from a few curious minor bots.
Now that we’ve covered what LLMs.txt is and how to create it for your site, we’ll cover some other ways that you can ensure AI crawlers can “read” your site. This is the foundation of answer engine optimization, or AEO.
As we touched on before, most AI crawlers do not execute JavaScript. Google’s crawler can render JS, but bots like ChatGPT’s or Claude’s essentially only fetch raw HTML. In fact, OpenAI and Anthropic’s bots still attempt to fetch some .js files, but they don’t run them. In one analysis, ~11.5% of ChatGPT’s requests were JS files (23.8% for Claude) that likely went unused.
Solution: Use server-side rendering (SSR) for key pages or provide a static HTML fallback. Deliver the core text in the initial HTML response so the bot sees it without needing JS. You can still use JS for interactive widgets, but critical text (product descriptions, article content, etc.) should be present in the HTML source. This way, even a less sophisticated AI crawler can read it.
AI crawlers can be impatient. Many operate with very short timeouts (often 1-5 seconds) when fetching content. If your webpage is slow or heavy, the bot might give up or only be able to grab part of the content before it times out.
Solution: Optimize your site performance. Compress images, use efficient code, and consider caching to speed up delivery. Aim for a sub-2 or 3 second time-to-first-byte (TTFB) to account for LLM bots.
On a similar note, surfacing important info high in the HTML is helpful. If an AI bot times out after a few seconds, you want it to have seen your key points or introductory paragraphs. In practice, this means having a clean <head> (not loading 50 scripts before content) and maybe a summary or intro at the top of your page that quickly communicates the page’s main topic.
AI models are better at parsing content when it’s well-structured. They don’t have the millions of human-like judgment calls that Google’s algorithm has developed over decades of evolution, they often just consume text as-is.
Solution: Use clean, semantic HTML. Proper heading hierarchy (<h1>…<h2>…) and clearly labeled sections help the crawler (and the AI) understand the context. For example, use <h2> for subheadings, <ul>/<ol> for lists, and mark up product details or FAQs clearly. Structured content is easier for an LLM to interpret correctly.
Additionally, include descriptive alt text for images (the AI might read this as part of the page content). Think of it like writing for screen readers: clarity and hierarchy matter. A well-structured page is less likely to confuse the AI, making it more likely the AI will be able to extract the right snippet for an answer.
Interestingly, AI crawlers tend to be less “seasoned” in avoiding dead links. Some reports show that AI bots fetch more 404s (broken URLs) than Googlebot does; possibly because they exhaustively try URLs (like old archive links or variations) or have a smaller crawl budget per site.
Solution: Maintain good site hygiene. Fix or redirect broken links, and keep your XML sitemaps up to date. If you move content, set up proper 301 redirects so both users and bots find the new location. Having an up to date sitemap.xml can guide AI crawlers to valid URLs and reduce the likelihood of them wandering into 404s.
Be sure to also use consistent URL patterns and avoid unnecessary URL parameters; it reduces the chance of the bot crawling invalid versions of your pages.
Answer engines are looking for accurate, relevant information. If your content is outdated or full of fluff, an AI might either ignore it, or worse: use it and give users incorrect info.
Solution: Treat content quality as a priority. Ensure all facts and data on your high-traffic pages are up to date and accurate. Regularly audit pages that drive a lot of AI queries (e.g. a popular how-to blog post or product page) to update any stale information.
Also, be concise and clear in writing; AI models might get confused by rambling text or marketing jargon. Write in a way that supports the extraction of a straightforward summary or answer. Consider adding an FAQ section or bullet-point summary on important pages; these are great for both featured snippets and AI answers.
Finally, make sure you’re not accidentally blocking the very bots you want to welcome. Overly aggressive bot-blocking (via firewalls, robots.txt, or meta tags) can keep AI crawlers out. For example, if your robots.txt bans all but Google, or if you use a generic bot blocker, LLM crawlers might be getting a “No Entry” sign.
Solution: Review your robots.txt and any bot security rules. Whitelist the legit AI agents (we’ll cover how in a moment). In general, avoid blanket disallow rules that include AI bots. Unless you have a specific reason to exclude them, let them roam like normal search bots. It’s a balancing act: you might block malicious scrapers, but don’t inadvertently snub GPTBot or its friends.
With the technical groundwork laid, let’s turn to LLMs.txt, a new tool developed specifically with AI bots in mind, and how it fits alongside the trusty robots.txt.
Every SEO practitioner knows about robots.txt. It’s a simple text file at your site’s root that tells crawlers what they can or can’t access. While LLMs.txt is about offering content to AI, robots.txt is about controlling access. In the context of AI bots and answer engines, you should treat robots.txt as your first line of defense and a tool to enable access for “good” bots.
Here are some best practices for robots.txt with AI in mind:
Given that LLMs.txt isn’t widely adopted as of yet, If you want to be included in AI-generated answers, allowing AI crawlers is crucial. By default, if you haven’t blocked them, most AI bots will crawl like any other crawler. But it’s worth explicitly checking your robots.txt to ensure you’re not unknowingly blocking important ones.
For example, if your file has Disallow: / under a wildcard User-agent: *, then no GPTBot and no Claude bot can crawl the domain. If you previously only allowed Google and Bing, you’ll run into the same issue. Review and update your directives. A simple approach is to allow all AI crawlers by default, and only disallow specific bots or sections as needed.
Currently known “good” AI user-agents you might want to allow (or at least not block) include: GPTBot (OpenAI), Claude or Anthropic (Anthropic’s bot), Google-Extended (Google’s AI data crawler), BingBot (Bing’s regular crawler, used by Bing Chat as well), and possibly others like CCBot (Common Crawl, which many AI models train on). If you see other AI bot names in your logs, investigate them; some might be legitimate new models.
Not every site will want all AI bots. Some sites choose to disallow GPTBot, for instance, if they don’t want their content used in ChatGPT’s training or output. OpenAI provides a way to do this via robots rules (GPTBot will obey Disallow). Similarly, Google introduced Google-Extended, a token you can disallow to prevent your content from being used to improve Bard or Vertex AI. For example, your robots.txt might include:

Or to block OpenAI’s bot entirely:

Keep in mind, blocking all AI crawlers is a double-edged sword. It protects your content from being consumed by AIs, but it also means you won’t appear in their answers at all. Outright blocking AI bots can make you miss out on traffic and sales opportunities that come from AI recommendations.
In other words, if you slam the door on these bots, your competitors’ info might be used to answer users’ questions instead of yours. So, decide strategically: opt out only if you have specific concerns (e.g., sensitive data, or you have an alternative strategy for AI).
Some robots.txt implementations allow a crawl-delay directive to tell bots to slow down. Google ignores this, but Bing and some others respect it. If you find an AI crawler is hitting your site too hard, you can try adding, “Crawl-delay: 5” under its user-agent to space out requests. However, keep in mind that not all AI bots will honor it (many might not even read it).
Another approach is using a server-side firewall or bot management tool to rate-limit specific agents. For example, Cloudflare’s firewall can challenge or block excessive bot traffic. Use these measures if an AI bot is causing performance issues, but again, allow reasonable access for those you deem beneficial.
If you’ve implemented an LLMs.txt, make sure your robots.txt and LLMs.txt policies align. Robots.txt rules override LLMs.txt rules: if you disallow a section of your site in robots.txt, listing it in LLMs.txt won’t help because a polite AI bot won’t fetch it. For instance, if your API docs are in /api/ and you put them in LLMs.txt, but your robots disallows /api/ to all bots, GPTBot will not retrieve /api.md.
The best practice here is to coordinate these files: use robots.txt to truly restrict private or irrelevant content, and use LLMs.txt to shine a light on the content you do want to be visible. Think of it this way: robots.txt is the gatekeeper, LLMs.txt is the tour guide. Together, they can direct an AI crawler efficiently. It’s a “here’s where you can go” (robots.txt) and “here’s what’s worth looking at” (LLMs.txt) relationship.
A well maintained robots.txt is a sign of site health, an SEO ranking factor, and a general best practice. This includes listing your sitemap URL in robots.txt (so crawlers, including AI ones, can find all of your pages easily), and ensuring there’s no outdated or contradictory info. Don’t leave old directives for bots that no longer exist, and do include directives for new ones as they emerge (if necessary).
It’s also wise to monitor your server logs for bots hitting robots.txt. If you see an AI user-agent requesting pages but never checking robots.txt, that bot might not be respecting rules (red flag!). Most legitimate crawlers will fetch robots.txt first; if an AI crawler doesn’t, you might treat it as a bad bot and handle it accordingly.
Robots.txt remains a critical tool in the era of AI. Use it to ensure that AI bots can access your content (or to block them, if that’s your strategy), and to prevent them from accessing parts of your site you’d rather keep out of the AI index. It’s not an either/or with these types of files; you can and probably should use both: robots.txt to set the boundaries, LLMs.txt to offer a content roadmap within those boundaries.
Bringing it all together, here’s a step-by-step checklist to implement these practices for your site:

Based on your business goals, decide if you want to opt out of any AI uses. If you’re uncomfortable with your content being used in AI training or answers, use robots.txt to disallow those bots.
For most, the goal will be to include your content, so you’ll keep things open. But make conscious choices; for example, you might allow AI crawlers on public blog content but disallow them on user-generated content sections or certain tools.
(Remember, if you disallow widely-used bots, consider the impact: you might be absent from answers on ChatGPT, Gemini, etc.)
Now it’s time to review your existing robots.txt file.
Before inviting more bot traffic, ensure that your site will be able to handle it. Implement the crawlability solutions discussed previously:
This step is essentially making sure the house is in order for any bot, AI or otherwise. It benefits SEO and AEO alike. Key things: fast response times, clean HTML, and updated sitemap and internal links.
Especially on your high-traffic pages, review the content with a critical eye:
If you have pages that get a lot of search traffic (from Google) for question keywords, those are prime candidates to be used in AI results; make sure they have well-structured answers. It might help to add an FAQ section or a summary paragraph that directly answers common questions (this can feed both featured snippets and AI answers).
Also consider adding appropriate structured data (like FAQ schema, HowTo schema, etc.) to these pages to formally mark them up.
If you choose to implement LLMs.txt:
If you have the capacity, create simplified Markdown versions of the pages you listed in LLMs.txt (as separate .md files on your server). This isn’t strictly necessary, but it enhances the effectiveness of LLMs.txt.
These could be generated automatically from your HTML (some static site generators or docs platforms can output MD). Ensure these .md URLs are accessible and included in LLMs.txt. (If you don’t do this, the AI will at least fetch the HTML pages, which should already be optimized from Step 3.)
Cross-verify that any page you put in LLMs.txt isn’t accidentally disallowed in robots.txt. Additionally, add a line in robots.txt to allow the llms.txt file itself if you have a catch-all disallow (you want bots to fetch this file).
For example, you might include: Allow: /llms.txt under your AI bot user-agent rules, just to be explicit. Generally, if your site is open, it’ll be fine, but it’s also always good to ensure that there is no conflict between the two files.
After implementing these changes, keep an eye on your server logs or analytics.
Continue to monitor your site’s performance: if bot traffic spikes, make sure your server can handle it. If not, you might need to introduce a Crawl-delay or use your hosting firewall to mitigate overly aggressive hits.
On the flip side, watch for any increase in AI-driven referrals; for example, if Bing Chat or an AI summary starts sending users who click through the source citation. This can be hard to measure, but any uptick in referral traffic from those platforms is a good sign.
Keep an ear out for announcements. If Google or OpenAI start officially supporting something like LLMs.txt or new meta tags, you’ll want to adapt quickly.
Likewise, new best practices for AEO (Answer Engine Optimization) are emerging as marketers experiment. For instance, using IndexNow (a protocol to instantly notify search engines of new content) has been suggested as a way to get Bing (and thereby ChatGPT via Bing) to pick up your updates faster.
Ensure you’re looped in by following SEO news or joining relevant communities. Adapting early can give you an edge. (And if you’re here, it’s clear that being ahead of the game is something that’s important to you!)
This is more of an ongoing principle than a step, but it’s worth ending on. No amount of technical tweaking will help if your content isn’t actually useful or relevant to what people ask.
Remember that AI answer engines favor content that directly answers questions and has authority. So, as you implement all the above, continue to craft content that is high-quality, authoritative, and answer-oriented.
That means understanding the questions your audience is asking (keyword research can help, as well as analyzing Bing Chat or Google’s AI queries in your niche if available) and tailoring pages to answer those. The combination of excellent content and solid technical accessibility is what will ultimately get your site featured in AI-driven results.
By following this checklist, you’ll cover both the technical and strategic bases needed to optimize for AI bots and maintain good SEO practices. In many ways, AEO is an extension of SEO: a lot of the fundamentals (site speed, clear structure, quality content) are the same, but there are new nuances like LLMs.txt and catering to how AI models consume data.
The world of search is no longer just about pleasing a ranking algorithm; it’s also about collaborating with AI algorithms that generate answers. Preparing your site with robust crawlability, using tools like robots.txt and LLMs.txt smartly, and keeping your content optimized for direct answers will position you to thrive in the era of answer engines.
As LLMs continue to evolve, websites that bridge the gap (by making their content both human friendly and AI-friendly) stand to gain the most visibility. So, take these steps, keep experimenting, and you’ll be well on your way to mastering Answer Engine Optimization for your brand.
.svg)
.svg)

.svg)

.svg)