.svg)
Get a Demo
Interested in trying Goodie? fill out this form and we'll be in touch with you.
Oops! Something went wrong while submitting the form.
.svg)
.svg)


AI is doing more than reading all the internet has to offer; it’s also listening.
We’ve already talked about how social platforms shape what AI knows: how Reddit threads, TikTok captions, and YouTube comments inform what shows up in an AI’s response. But that’s only half the story. AI models also ingest and synthesize audio data, podcasts, interviews, YouTube videos, and other spoken content to generate more human, more contextual answers.
In other words, every word spoken into the mic can potentially train or trigger an AI response.
Let’s unpack how AI “hears” podcasts and videos, how transcripts transform into citations within chatbots, and what you need to do to get AI to understand what you’re talking about. Because today, the web is read, watched, and listened to.
Before AI search tools like ChatGPT, Perplexity, Gemini, and a handful of others can understand your podcast or video, they need to hear it. Well, not literally, but through transcripts.
Modern multimodal models like GPT-4o, Gemini 1.5, and Claude Sonnet use Automatic Speech Recognition (ASR) systems like Whisper, Deepgram, and Google’s Speech-to-Text to convert spoken words into text. The text is then tokenized (broken down into data units that the model can interpret), embedded into a semantic vector space (turned into math soup to match a flavor to a future question), and stored alongside written content from across the web into the world’s tiniest virtual-ish filing system.
To put it as simply as possible, audio becomes language data: searchable, indexable, and ready to be cited.
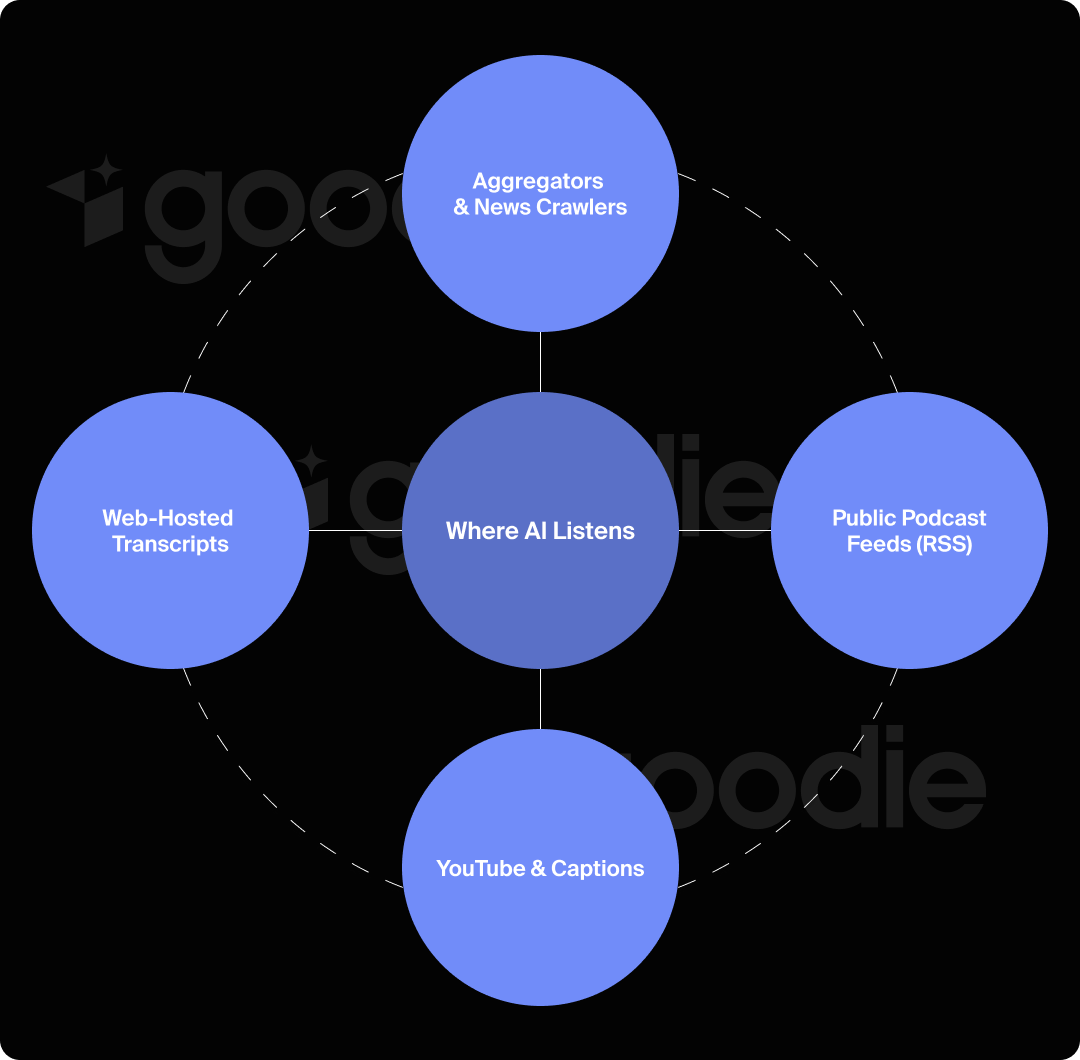
AI search tools pull from a surprising number of places for audio data:
Once the AI model has converted audio to text, it analyzes entities, sentiment, and context to determine what information is relevant to what query.
Basically, the pipeline looks like this:

Audio File → Transcription (ASR) → Tokenization & Embedding → Retrieval Layer → AI-Generated Response or Citation
For brands, this means audio is now multipurpose: it serves up content and is used as data to train and inform AI search engines. And since auditory content trains AI search engines, properly optimizing it ensures your brand gets surfaced.
Remember the simpler days when links were basically digital currency? Every backlink whispered to Google, “Hey, this source is trustworthy.” The days may not be so simple anymore, but transcripts are essentially today’s version of backlinks.
When your spoken words get transcribed, tagged, and published online, they become part of the interconnected web of data AI models learn from. Clear, well-structured transcripts tell AI models who said what, when, and why it matters, the same way links tell Google which pages deserve authority.
The cleaner and more consistent the transcript data is, the easier it is for AI engines to:
AI systems look for contextual clues inside transcripts: speaker names, recurring entities, timestamps, and supporting metadata.
If your podcast mentions “AI visibility tracking by Goodie” in multiple episodes and those transcripts live on a site that also talks about AEO, the model starts connecting the dots:
“This source = authority on AI visibility.”
That’s how a podcast becomes quotable inside an AI’s response; your words evolve from content to evidence.

Transcripts with broken formatting, inconsistent speaker labels, or missing context often get treated like the SEO equivalent of a 404.
To make your podcast AI-friendly:
Think of it as the digital version of enunciating clearly so the machines don’t misquote you.
So if you want AI to hear you loud and clear, you’ve got to speak its language.
The better your audio quality, structure, and metadata, the easier it is for AI to transcribe and interpret your content accurately. Consider this your checklist for the multimodal web:
AI can’t index what they don’t understand. Even the best transcription tools (like OpenAI’s Whisper or Riverside) struggle with background noise, heavy music beds, or five people talking at the same time.
Best Practices:
Even slight boosts in transcription accuracy compound into better entity recognition, meaning AI is more likely to “understand” who you are and what you said.
Audio alone isn’t enough. AI relies on the text layer that sits beneath your episodes.
Checklist:
If you include transcripts within expandable “show more” blocks, ensure the content still renders in HTML. Hidden text is invisible to most crawlers and AI scrapers.
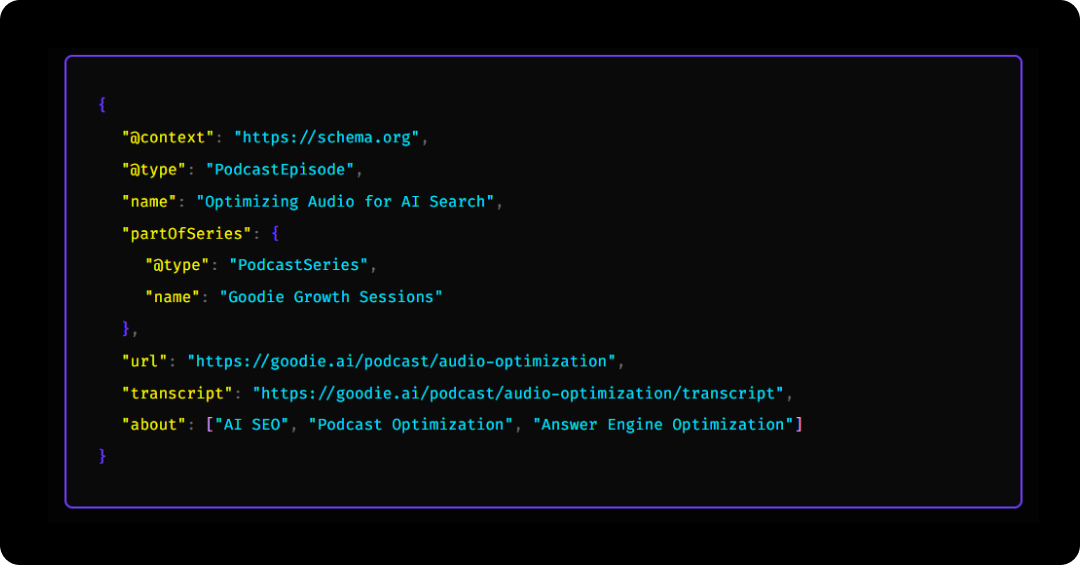
Schema is how you tell search engines and AI models exactly what your audio contains.
Use PodcastSeries, PodcastEpisode, and AudioObject schema to define:
Example snippet (simplified):
AI models build trust through ✨consistency ✨
When a person, brand, or product is referenced in a podcast, it's very important that the entity appears (‼️spelled the exact same way‼️) across your website, socials, and transcripts.
Tactical ways to strengthen entity clarity:
Each entity mention is like a digital breadcrumb helping AI connect the audio back to a broader authority footprint.
Do not think that once you’ve published, it's a “set it and forget it” kind of deal (never the case in marketing). You need to reiterate and optimize.
Luckily, I know the perfect tool for the job: Goodie’s AI Visibility dashboard. You can monitor any mentions of your brand (even in podcast format).
Other helpful tools include:
Key Takeaway: The clearer your sound, structure, and signals, the easier it is for AI to hear, index, and quote you. Optimization isn’t about gaming the system, it’s about making your voice machine-understandable.
“But Julia, what if my brand doesn’t have a podcast?”
To that I say, not every brand needs a podcast, but every brand does need a presence in audio conversations.
As AI engines learn to interpret sound, any mention of your brand, founder, or expertise across podcasts, interviews, and even webinars can become part of the training data and retrieval layer that powers multimodal search.
In short, you don’t have to publish the episode; you just need to be a part of the story.

AI models identify “citable moments” in audio the same way they do in text: short, structured, and attributed insights that sound like they belong in an answer.
To increase your odds of being referenced:
Think like a journalist. The cleaner your quote sounds when read back, the more likely it is to be cited by humans and machines.
You can earn AI citations by becoming part of someone else’s content. When those recordings are transcribed or summarized online, you inherit discoverability.
Tactical plays:
When those episodes get scraped or transcribed, your brand name becomes a structured text entity that AI can associate with that topic cluster.
Think of it as the "audio version” of digital PR. You’re not chasing backlinks. You’re earning sound links (get it?).
Even if your company doesn’t record audio, your voice can exist in multiple searchable layers:
Every caption, transcript, or audio embed you host creates another entry point for AI discovery and another chance to be cited.
The real unlock is knowing where your voice travels.
Use:
Over time, you’ll start to see which shows, creators, and topic clusters drive the most AI visibility so you can double down where it matters.
Every audio appearance, even a 10-second mention, adds to your AI reputation graph.
Store and tag your audio content the same way you track backlinks or press hits:
The more consistent your data, the more likely AI models will recognize your brand as a verified source across modalities: text, video, and voice.
So no, you don’t have to host a podcast to be heard by AI.
You just have to make the places you are heard (guest spots, mentions, panels, or clips) are clear, consistent, and machine-readable. In a world where LLMs learn from every frequency, silence means invisibility.
Optimization used to mean making sure Google could read you, but now it’s about making sure AI can hear you, too.
Podcasts, interviews, webinars, and short-form clips are data sources feeding the next generation of AI search. Every clean transcript, clarified quote, and consistent brand mention shapes how models like ChatGPT, Gemini, and Perplexity describe your expertise back to the world.
Whether you’re producing your own show or simply appearing on someone else’s, the principle is the same: the clearer your sound, the stronger your signal.
Optimizing for the multimodal web means treating audio like our newest frontier in search: structured, contextual, and entity-rich. Because if AI learns from what it hears, your voice is part of the index.
.svg)
.svg)

.svg)

.svg)