.svg)
Get a Demo
Interested in trying Goodie? fill out this form and we'll be in touch with you.
Oops! Something went wrong while submitting the form.
.svg)
.svg)



It’s safe to say LLMs have shifted the world as we know it. However, they’ve also kind of grown up on the assumption that the internet was open terrain: scrapable, indexable, and fair game for training.
Unfortunately for the Anthropics, OpenAIs, and Googles of the world, that era is seemingly over. Communities, social networks, and creator platforms are restricting access, formalizing licensing, and treating behavioral data as proprietary infrastructure rather than public input.
At the same time, non-AI-native platforms are not only defending that data against AI pioneers, but they’re also building their own AI search experiences on top of it. Platform-native AI trained on exclusive datasets is becoming the interface layer users consistently interact with, like TikTok’s Tako and in-app AI Search tool.
This is a shift that we’re coining as the LLM data wars: a quiet, yet consequential fight over who gets to train on what, who gets excluded, and ultimately, who gets to shape the answers users see.
Looking forward, an important question the industry as a whole will be asking is which models are allowed to learn and from where.
Note: In this article, we’re focusing on the systemic shift behind the changing and fragmenting of data access in AI. As platforms update policies, licensing agreements shift, and new AI interfaces launch, the dynamics will continue to evolve.
This analysis discusses why the shift matters, not just what happened.
Early LLMs were trained by ingesting massive amounts of publicly accessible data. Coverage and scale mattered more than permission. If content was available on the open web, it was generally treated as usable.
That approach mirrored the broader “move fast and break things” era of the internet, where data was treated as ambient infrastructure rather than owned material. However, as AI systems became more capable and more valuable, that assumption broke down, and people started getting very protective of the gold mine they realized they were sitting on top of.
Platforms began reassessing what unrestricted access actually meant. Data stopped being exhaust and started being leveraged. Open scraping gave way to licensing, gating, and selective partnerships.
The result wasn’t the end of large-scale training, but it was the end of default openness.
Once platforms started locking things down, the next move was inevitable: build intelligence directly on top of it.
Platform data isn’t just content for content’s sake. It’s behavioral signals, social graphs, engagement patterns, and contextual intent, and all that information loses its value when everyone gets a slice of the pie. Paired with native interfaces and first-party feedback loops, that data becomes almost priceless.
This is why so many platforms are building AI directly into their products. By keeping data and models together, they can turn raw behavior into recommendations and citations without losing context on the way.
For a long time, the promise of LLMs themselves felt universal. Ask the same question, get roughly the same answer. Differences were framed as model quality or tuning. We can no longer assume that.
As data access fragments, AI answers fragment with it, not because the models are “failing”, but because they’re being trained inside increasingly different information environments.
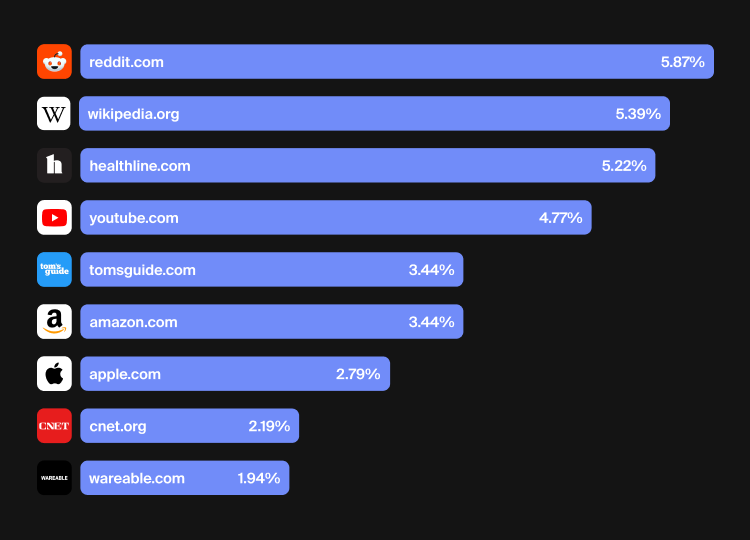
Ask the same question across different AI search tools today, and you’ll often see:
The wrong question isn’t one of accuracy, but more about exposure. Models trained on different slices of the information and internet pie develop different strengths, blind spots, pain points, and defaults. Over time, those differences compound, especially as closed ecosystems reinforce their own feedback loops.
We’re watching these platforms move from one shared internet to many competing interpretations of it.

From a user’s perspective, the LLM data wars are almost invisible. AI steel feels fast, fluent, and confident. But something important has changed.
Platform-native AI optimizes for convenience: fewer clicks, fewer sources, faster answers. That ease comes at the cost of perspective. When intelligence is trained on a single ecosystem, answers naturally reflect what that ecosystem can see and what it benefits from showing.
Trust is also shifting. Where users once evaluated sources, they now evaluate systems. If an answer sounds coherent and confident, it’s less likely to be questioned, even when it reflects a partial view.
In this case, users are essentially choosing which version of reality they query.
For brands, the LLM data wars change the rules of visibility.
In traditional search, visibility was largely a function of rankings. However, in AI search, visibility happens upstream, often before a click, if it even gets one at all.
AI doesn’t decide what to show in the moment, only a reflection of what they’ve already learned. That means brand visibility depends on:
A brand can rank well, publish great content, and still be underrepresented in AI answers if its signals aren’t present in the right data environments.
This creates a new risk: invisible influence gaps. When AI omits a brand entirely, competitors define the category and alternatives become defaults, without brands realizing it until downstream performance shifts.
The LLM data wars are about who controls the inputs that shape intelligence itself.
As platforms gate access, selectively license, and build directly into their existing ecosystems, LLMs stop reflecting a shared internet and start reflecting bounded worlds. Each becomes coherent, capable, yet incomplete in its own way.
This also isn’t just some temporary phase. This is a structural change in how knowledge is formed, mediated, and surfaced.
And it's why the most important question isn’t just which models are the smartest, but who that model is allowed to learn from.
.svg)
.svg)

.svg)

.svg)