Unless you’ve been living under a rock, you’ve probably noticed that AI is becoming increasingly integrated into all aspects of life, including online search.
When you search for something on Google, more likely than not, an AI Overview will be the first thing to pop up. Beyond AI Overviews, people are turning to large language models (LLMs) like ChatGPT for their search needs, as they start to prefer direct, synthesized answers over poring through a search engine results page (SERP).
With this information in mind, you’re probably wondering: where does AI get its data from, and how can I be part of it?
This isn’t just top of mind for you, but for everyone who wants to use these technological advancements to drive growth for their brand.
In this piece, we’ll lay out exactly how to be included in AI answers, and trust us; We’re the experts here.
What Are the Data Sources for AI?
Before we tell you how to be included, you need to know what’s included.
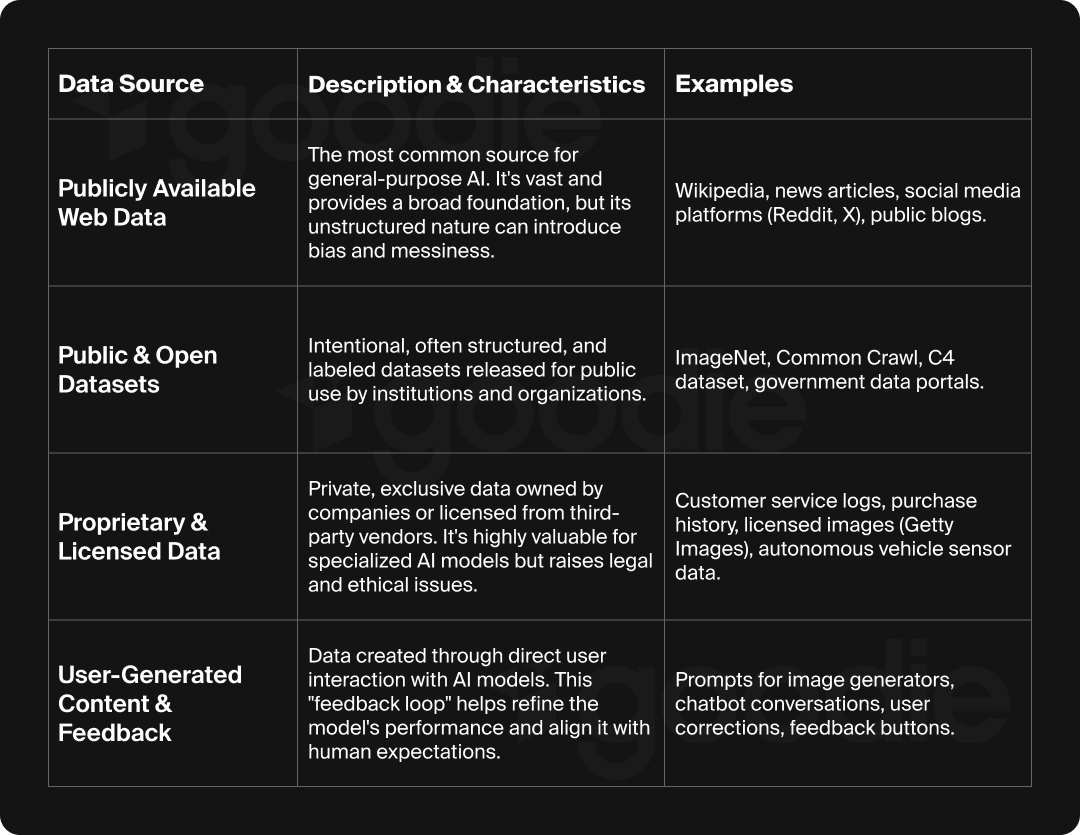
Publicly Available Web Data
This is the most common source for large-scale, general-purpose AI models. It’s collected using web crawlers or web scrapers that automatically browse and extract data from a huge variety of websites.
This includes text from sources like Wikipedia, news articles, and even conversations users are having on social media platforms and forums like Reddit. The sheer amount of this data provides a broad foundation for LLMs, but its unstructured nature means it can be messy, and the biases present in public discourse can possibly be perpetuated by the AI model.
Public Use Datasets
These are datasets that have been intentionally created and released by research institutions, governments, or organizations for public use, often structured and labeled.
Notable examples include ImageNet, a massive dataset of over 14 million images used to train computer vision models, and the C4 dataset, a text collection derived from the Common Crawl web scrapes. The availability of these datasets is a cornerstone of the open-source AI community, allowing researchers and developers worldwide to build upon each other’s work without having to collect data from scratch.
Proprietary & Licensed Data
Companies often use their own internal data to build specialized AI models that give them a competitive edge. This can include valuable information like customer service logs and purchase history. Additionally, some companies, like Getty Images, license their copyrighted content to AI developers for a fee.
The value of this data lies in its exclusivity, but its use brings up legal and ethical challenges, particularly concerning data privacy and ownership.
User-Generated Content & Feedback
Every time you interact with AI, you’re potentially providing new data it trains itself on. The prompts you use in an image generator, the questions you ask a chatbot, and the corrections you provide to its output are all forms of data. This process, often called a “feedback loop,” helps refine the model’s performance and align it with each user’s expectations.
How Can I Be a Part of AI’s Data?
Answer Engine Optimization (AEO) is the practice of optimizing your content to be cited in an answer by LLMs like ChatGPT, Gemini, and Perplexity, and SERP features like AI Overviews. Instead of competing to rank on a SERP, the goal is to be the authoritative source that AI uses to formulate a response, requiring a shift in how you structure and present information.
How Can I Become an AI Citable Source?
To make your content a top choice for AI models, you must focus on delivering clarity, authority, and structure in your content.
- Provide Direct, Concise Answers: AI models are designed to give users a single answer without making them click through multiple links. To be the source for that answer, you must provide it immediately and succinctly. You can do this by:
- Using question-based subheadings (H2s, H3s, H4s) that directly mirror what users are searching for (e.g., “What are the data sources for AI?”).
- Immediately following the heading, writing a direct answer in a short paragraph (30-60 words). This is crucial for winning a spot in an AI Overview.
- Build Trust & Authority (H-E-E-A-T): AI models, especially those from Google, are trained to prioritize content from helpful, credible sources. You can do this by:
- Explicitly demonstrating your expertise by citing reputable sources, linking to academic papers, or mentioning your personal experience with the topic at hand.
- Ensuring your content is factually accurate and up-to-date. Regularly optimize your most important pages to signal freshness, a key factor for AI crawlers.
- Use Schema: This is a technical signal that tells AI exactly what your content is about. You can do this by:
- Implementing FAQPage schema for question-and-answer content, HowTo schema for step-by-step guides, and Article schema for blog posts. This code helps AI understand the relationships between different pieces of information on your page.
- Researching what other schema to include on your site on Schema.org.
To help with this, you can use Goodie, which offers AI visibility and optimization recommendations for your AEO efforts. Goodie can even help you write content if you’re not sure where to start.

How Can I Target Different Datasets?
We previously outlined the types of data that AI models are trained on and used to generate answers. You can influence this by creating targeted content to become an authority in a specific niche.
Public Web
This is the foundation of generative AI’s outputs. To be visible here, you need to create comprehensive, well-structured content that covers broad topics.
To do this, you can use a hub-and-spoke model:
- Pillar Pages (The Hub): This is a long-form, comprehensive guide that covers a broad topic at a high level. Think of it as your “ultimate guide” or “beginner’s guide.” For instance, a pillar page on “Generative AI” would define key terms, explain different types of models, and provide an overview of their applications. This page is optimized for broad keywords like “generative AI” or “what is AI data.”
- Cluster Pages (The Spokes): These are individual articles that dive deep into a specific subtopic mentioned in the pillar page. They link back to the hub and to each other. For example, from your “Generative AI” hub, you would link to a spoke page on “text-to-image models,” another on “large language models,” and a third on “data privacy in AI.” These pages are optimized for more specific, long-tail keywords.
By building this interconnected web of content, you’re helping AI understand the relationships between your content, recognize your site as an authoritative entity on the topic, and ultimately, choose your content to cite in its answers.
Internal & Licensed Datasets
Although these datasets are usually private and inaccessible to the public, you can create content that mirrors the structured, expert-level data an AI would seek out.
You can do this by embracing the “living document” strategy:
This strategy involves creating unique, data-rich content on your website that you continuously update. This signals to AI models and search engines that your site is a reliable and up-to-date source of information.
- Create Original Research: The most powerful way to become authoritative to AI is to generate proprietary datasets of your own. This can be done by conducting surveys, analyzing industry trends, or publishing case studies. Content that’s unique and can’t be found anywhere else makes it a prime candidate for citation; just look at what we’re doing over on our blog.
- Publish It as a Living Document: Make your research publicly available on your site and commit to updating it regularly. AI models are trained to prioritize information that is fresh and well-researched. By consistently updating it, you signal that your content is a current source, much like a licensed dataset would be.
By adopting this strategy, you’re gaining a competitive advantage in AEO as you position your brand as a leading authority in your niche, increasing the likelihood of being cited. And if you need some extra support in this effort, Goodie can provide you with analytics to track how your content is performing in AI platforms.
UGC
AI crawlers index forums, social media, and review sites to understand human language and intent, which you can target by actively participating in these spaces.
Here’s how to effectively shape conversations on these platforms, increasing your likelihood of being cited:
- Engage on Q&A Platforms: Answer questions on forums like Reddit, Quora, and other discussion boards. These platforms are filled with questions people actually want to know the answers to, making them inherently natural. By providing helpful answers, you have the potential to position your brand and expertise directly within these public datasets, helping AI associate your brand with conversational information.
- Build Your Own Community: Create a community forum or comments section on your blog. The organic conversations that happen there, from questions and answers to discussions and debates, become a live dataset that’s singular to your brand. This not only builds a loyal audience but also creates a valuable, proprietary source of data that AI models can reference.
By strategically engaging on these platforms, you’re killing two birds with one stone; you’re providing value to users while simultaneously influencing the AI crawlers that scrape these public discussions.
Why Being The Source Matters More Than Ever
AI models are changing the very nature of search. The days of competing to rank on a SERP are being replaced by the need to be the source that an AI uses in its answers.
By creating content that is clear, authoritative, and well-structured, you are not just building a blog; you’re building a trusted dataset.
The future of AI depends on its data. Your choice to be an intentional, high-quality source of data ensures that the AI generates accurate, high-quality results.
If you’re ready to start building a dataset of your own, consider Goodie for these efforts.



