
.svg)
Get a Demo
Interested in trying Goodie? fill out this form and we'll be in touch with you.
Oops! Something went wrong while submitting the form.
.svg)
.svg)


Last Updated: February 2026
The LLM data wars didn’t start with a single lawsuit or licensing deal. They emerged gradually, as platforms realized that the data fueling AI systems was not longer just content, but lucrative, strategic infrastructure.
This timeline tracks key moments when access to LLM training data shifted: API restrictions, licensing agreements, legal enforcement, and the rise of platform-native AI.
This is a living resource. As new developments occur, we’ll update this post as the landscape continues evolving.
For a deeper analysis of why these shifts are fragmenting AI answers, see our companion piece: The LLM Data Wars: Why AI Answers Are Fragmenting.

By 2026, AI search has clearly moved beyond experimentation and into core commercial infrastructure. AI-driven search traffic grew 155.6% in 2025, with projections estimating it could funnel as much as $750 billion in US revenue by 2028. However, that growth isn’t evenly distributed.
ChatGPT continues to dominate overall AI search traffic, accounting for roughly 84.1% of trackable volume, but that dominance varies significantly by industry. At the same time, enterprise-facing systems like Microsoft Copilot saw explosive adoption, growing 25× throughout 2025, a sign that productivity and workflow-integrated AI was emerging as a parallel discovery layer, not a secondary one.
Adoption is also fragmenting sharply by vertical. Legal services saw roughly 15× growth in AI search, events-related use cases grew 20×, and insurance adoption surged nearly 90× year over year. These shifts reinforced a broader pattern: AI discovery is no longer general-purpose.
AI is becoming industry-shaped, with different models, data sources, and interfaces dominating different domains. Importantly, this shift wasn’t just about traffic volume. AI-referred visits were converting at 2-3× higher rates than traditional channels, suggesting that AI answers are shaping decisions before users ever reach owned properties.
At the same time, competitive differentiation among AI platforms increasingly hinged on licensed data depth, not just retrieval or reasoning quality. Perplexity AI expanded partnerships with financial data providers, including Benzinga, FactSet, Morningstar, and Quartr, underscoring how access to proprietary, high-trust datasets is becoming a prerequisite for relevance in certain categories.
Taken together, these trends point to a future where AI discovery is both massively influential and deeply fragmented, shaped less by a single “best model” and more by who controls the data, the interface, and the economic incentives underneath.
As the LLM data wars intensify, visibility becomes harder to reason about from the outside. Access rules differ by platform. Licensing deals are often private. Model behaviors shift without public notice. And AI answers increasingly reflect which data ecosystems a brand appears in, not just how well it ranks on the open web.
This timeline shows how quickly the ground is moving. It also highlights a deeper challenge: brands, publishers, and content teams can no longer assume how (or where) they’re being represented in AI answers.
In a fragmented AI landscape, situational awareness matters. Teams need to know:
Tools like Goodie are designed for exactly this moment, helping teams monitor AI visibility across models and platforms as access rules, partnerships, and data flows continue to shift. Not to game the system, but to understand it.
Because when data access determines visibility, visibility itself needs to be observable.
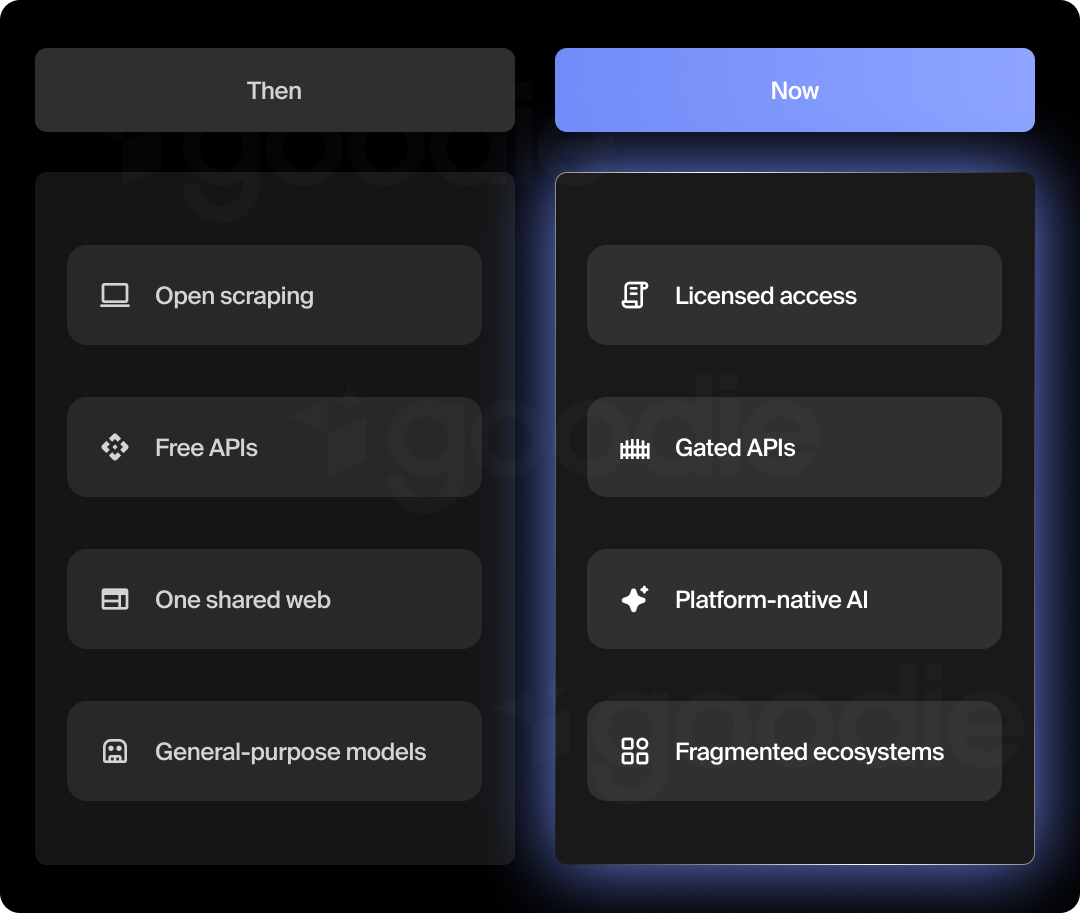
Taken together, these events show that the LLM data wars aren’t a one-time disruption, but a structural shift in how intelligence is built, governed, and monetized.
What was once open infrastructure is now negotiated access. What once powered general-purpose models is increasingly locked behind platform boundaries. As a result, AI answers are fragmenting into ecosystem-specific views shaped by licensing, policy, and economics.
This timeline will keep evolving as new deals, lawsuits, platform AI launches, and regulations emerge. But the core dynamic is already clear: control over data increasingly determines control over answers.
For brands, publishers, and product teams, the challenge is understanding how these shifts affect visibility and representation inside AI systems. As discovery moves upstream, knowing where and how you appear in AI-generated answers becomes table stakes.
That’s why tools like Goodie exist: to make AI visibility observable as the ecosystem continues to fragment.
We’ll continue updating this timeline as the data wars unfold, because in an AI-shaped web, understanding what changed and what it means is half the battle.
The LLM data wars refer to the growing conflict over who can access, license, and control the data used to train large language models. As platforms restrict scraping, sign exclusive licensing deals, and build their own AI tools, access to training data has become a competitive and economic lever, not a given.
As AI systems became commercially valuable, platforms realized their data was strategic infrastructure. Restricting access allows platforms to:
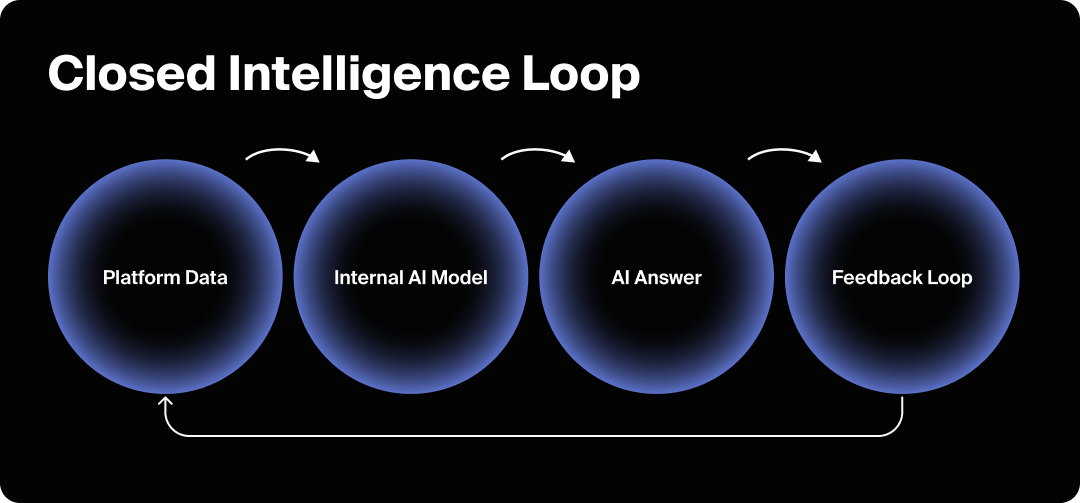
AI models reflect what they were allowed to learn from. When data access differs across platforms and partnerships, models develop different strengths, blind spots, and defaults. The result is fragmentation: the same question can produce different answers depending on the AI system you use.
It’s both, but the long-term impact is economic and structural. Legal actions and regulations enforce boundaries, while technical and architectural choices determine how models adapt. Together, they reshape how intelligence is built and surfaced at scale.
Visibility is no longer guaranteed by rankings alone. Brands and publishers can be well-known in one AI ecosystem and invisible in another, depending on where their data appears and how it’s licensed. This creates new risks around omission, misrepresentation, and lost influence in AI-driven discovery.
.svg)
.svg)

.svg)

.svg)





